1.0 There are already lots of CD rippers. Why write another?
Whilst it's true that there are lots of CD rippers out there, none of them met my specific ripping and tagging needs very well. My favourite CD ripper on Linux, for example, is abcde. It does a superb job of ripping a CD safely (that is to say, it cares more about accuracy than speed). But it spends a lot of time getting CD metadata (composer, work name, track titles and so on) from online CD databases and then prompting you to edit it in not very obvious ways. The metadata sourced for pretty much any classical CD you can think of is almost always complete rubbish, so abcde spending all that time and effort fetching and applying that metadata to my music files is a complete waste of time, as far as I'm concerned. On the other hand, it's true that abcde can be configured not to consult those online databases at all, which is excellent news... except that then your ripped music is left with absolutely no metadata at all.
I wanted a happy medium of allowing myself to specify some metadata, but not to have to fight bad online sources of metadata in the process!
Abcde is also very powerful and flexible, in that you can configure it to rip to MP3, FLAC or pretty much any other audio codec you like… but that flexibility is just a liability for me, since I only ever want to rip classical music to FLAC. So again, Abcde is an excellent ripper -but it's got features I don't need or want, and lacks one or two I really require.
The same is true for practically any other ripper out there. They all, in one way or another, spend time and effort doing things I don't want them to do, or not doing things I really need them to do! Classical CD Ripper (CCDR) gets the balance right (for me, at least!)
2.0 What makes this specifically a "classical" ripper?
It's designed to rip CDs carefully and accurately to make near-perfect digital copies of a CD, using a lossless audio codec (i.e., FLAC). It doesn't rip to MP3, for example, as some of the acoustic information from the music signal is discarded when creating an MP3 version of it. In using FLAC, this ripper produces files which are about half the size of the 'raw' audio signal on a CD, but they still contain every bit of information the original signal had on the CD. This lossless approach to digitizing music is not something that's unique to classical music, of course; but loss-less digitization is arguably more important for the wide dynamic range of classical music than it is for the much-more steadily-loud non-classical genres.
Another thing about this ripper is that it makes no attempt whatsoever to fetch metadata about your music from online databases or repositories since, without exception, all online metadata sources are completely useless for tagging classical music digital files. Other programs that do fetch online metadata will eventually have you listening to George Solti's Das Rheingold, for example; or getting lost in Murray Perahia's Goldberg Variations. Those who listen to classical music tend to think that Richard Wagner and Johann Sebastian Bach should get a rather more prominent mention in the metadata than that!
This means that the Classical CD Ripper outputs a set of unnamed, largely untagged, FLAC audio files -and it's left to you to use third-party programs to carefully edit and curate the metadata you want associated with them. That way, the metadata will end up correct and properly meaningful.
CCDR will also not talk about “artists”, “songs” or “tracks” unless it is technically accurate to do so. In the world of classical music, we have composers, works, pieces, movements and so on. CCDR uses this sort of terminology.
One other feature I'll mention which I think is more appropriate to classical music than any other type: quite often, we rip works which are supplied on multiple CDs. Think of Götterdämmerung, for example, which is usually supplied as a 4-CD boxed set. A lot of other rippers will regard the CD as the atomic unit of data. They will, therefore, tend to rip each CD with its tracks starting at '1'. But in the world of classical music, we only care that there's one 'opera' and we want its individual tracks numbered sequentially from beginning to end, no matter what CD they happen to have been supplied on. So, CCDR will allow you to specify a 'track ofset' when ripping CD2 of the boxed set so that its tracks will follow on sequentially from wherever CD1 got to; repeat with different and ever-incrementing offsets for the third and subsequent CDs in a set.
3.0 Can I use CCDR on non-classical music CDs?
Of course you can. CCDR's features are certainly tailored to those interested in classical music, but they can be used equally well by someone who enjoys all sorts of non-classical music. The program won't throw fatal errors the minute it sees a Michael Buble, Tony Bennet or Ariana Grande CD, for example!
4.0 What is metadata?
Metadata is simply “data about data”. In other words, the data you're actually interested in, in this context, is the audio contained within a digitized FLAC file. Put even more simply, the data we care about is music. But metadata describes this music. It tells us, for example, that it's by Beethoven or Mozart; that it's a concerto not a symphony; that Colin Davis is conducting, not Simon Rattle. And so on.
In the world of digital audio, this 'data describing the music' is stored within the audio file itself, in specially reserved sectors of the file, called 'tags'. There are separate tags for each piece of metadata. There is, for example, a 'Composer' tag, a 'Track Number' tag, an 'Album Name' tag and a 'Track Title' tag… and many others.
For a music collection to be easily navigable, readily understandable and delightfully playable, the metadata within your digital music files needs to be accurate, precise and consistent. It's no good, for example, labelling 'Beethoven' as the composer of Symphony No. 5 one minute and 'Ludwig van Beethoven' as the composer of Symphony No. 6 the next: “B” is nowhere near “L” in the alphabet -so if you did that sort of tagging, and then decided to organise your music collection by composer name, the two symphonies will end up miles apart from each other, with one near the top of the list and the other buried in the middle (because that's where "B" and "L" tend to come in the alphabet!)
In non-classical music, the tags can generally be a bit more relaxed, in the sense that if you are a fan of Paul McCartney, you're going to have music by him filed under 'B' (for Beatles) one minute, 'W' (for Wings) the next and 'P' (for Paul) the other. Beethoven tended not to change 'artist name' quite so frequently, though!
Correct and precise metadata is vitally important when you are dealing with classical music in a way it isn't quite for other types of music, because classical music collections are sorted and organised in precise ways which bad metadata will prevent working properly.
5.0 Why don't you fetch and use metadata from the Internet?
Because it's always rubbish. Here, for example, is what abcde makes of a 2002 recording of William Walton's Belshazzar's Feast (which happens to be paired with Ralph Vaughan Williams' Job):
Retrieving 1 CDDB match...done.
---- Various Artists / Walton & Vaughan Williams ----
1: Thus Spake Isaiah
2: If I Forget Thee, O Jerusalem
Well, it found a match, which is nice. But left to its own devices (as a lot of other rippers give you little choice about), it would tag these music tracks as being by someone called “Various Artists”. Store that on disk and let a media player catalogue and play it and you'll end up with this:
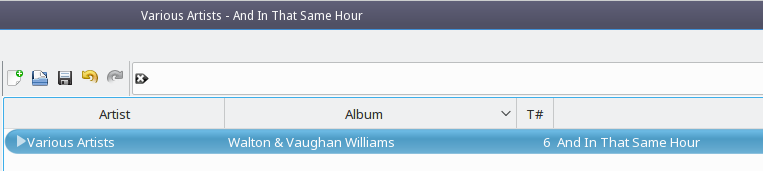
Note how the window title bar displays “Various Artists - And In That Same Hour”. It's (a) not very informative and (b) violates most rules of English grammar I can think of: capitalising words like 'in', 'that' and 'same' is an odd understanding of the basic rules of capitalisation, it seems to me! Meanwhile, in the main body of the player, the artist is declared to be 'Various Artists' and the piece of music I'm playing is just 'Walton & Vaughan Williams'… not a whisper that this might be a part of Belshazzar's Feast, then! Nor, indeed, that Belshazzar's Feast is by William Walton and Vaughan Williams had nothing to do with it!
In short, it's all horribly wrong, vague, mis-typed, mis-spelled, inconsistent rubbish …and is therefore frankly not worth fetching in the first place.
To be fair, abcde does offer you a chance to edit the metadata: but in a command-line text editor which (by default is vi-based!), that's easier said than done. Even on a good day, in nano, you are asked to edit this sort of data:
# 340815
#
# Disc length: 4753
#
# Revision: 1
# Processed by: cddbd v1.5.2PL0 Copyright (c) Steve Scherf et al.
# Submitted via: fre:ac v1.0.17
#
DISCID=33128f15
DTITLE=Various Artists / Walton & Vaughan Williams
DYEAR=2002
DGENRE=Classical
TTITLE0=Thus Spake Isaiah
TTITLE1=If I Forget Thee, O Jerusalem
TTITLE2=Babylon Was A Great City
TTITLE3=Praise Ye
Is it obvious from that lot that something labelled DTITLE is likely to become both the 'album name' and the artist? Where do you set 'Composer', for example? Again, not obvious. So, editing that which has been fetched from the Internet is not something that's trivially done, even when the ripping program gives you an opportunity to do it.
The short version is, therefore: I think it's better to start clean, have the ripper add bare-minimum metadata of your own choosing and afterwards use other, third-party, GUI tools to set everything else correctly.
6.0 What metadata do we get to set, then?
Quite a bit; in fact, nearly everything you would need to make sense of the music in most music player/managers, except for the track titles (which need setting after the rip, using whatever tagging software you prefer). We don't bother setting esoteric information like the recording engineer or the key of the work, though!
You are asked 5 questions about the work you're ripping:
-
It's name
-
Who wrote it
-
Who's conducting it
-
What genre it belongs to
-
What year it was recorded.
The 'who wrote it' answer is used to populate the Composer and Artist tags. The 'name' becomes the 'Album', along with the surname of the conductor you mention. Thus, War Requiem conducted by John Eliot Gardiner, becomes War Requiem (Gardiner). The conductor's name is also entered into the Comment tag, though it will need to be fleshed out later, using other tagging tools, with further details of the complete set of performers.
Track numbers are set automatically, though you are allowed to specify a 'track offset' by which physical track 1 (say) becomes labelled as ripped track 15 (or whatever other number you choose).
The question about genre is used to populate the “Genre” tag. It should be things like 'Concerto', 'Orchestral', 'Opera', 'Vocal' and so on -though, naturally, any free-form text is actually permitted.
The “Encoded By” tag is also set to indicate that CCDR was used as the ripping tool (I needed a way to tell which bits of my own collection had been ripped accurately by CCDR versus those bits which hadn't).
Naturally, you are only asked the questions about piece name, composer and so on once -which could be considered a problem if you've got a CD with multiple works by different composers. In that case, however, you can choose to select only some of the tracks on the CD to be ripped; the answers to the questions you supply can be correct for just those tracks. Then you can choose to not eject the CD at the end of that rip, and re-run CCDR to rip the other tracks with different answers to the questions that are now appropriate for the second set of tracks to be ripped. Keep re-ripping different parts of the CD with different answers supplied until the entire CD is ripped -and for the last ripping run, choose to eject the CD when finished.
7.0 What type of tag do you set?
The subject of tagging digital audio files can get rather complicated!
If you create (lossy) MP3 files, you are supposed to tag them with “ID3” tags. If you create (lossy) Ogg Vorbis files, you are instead supposed to tag them with “Vorbis” tags. And when you create (lossless) FLAC files, you are supposed to tag them with… Vorbis tags.
Where it starts getting tricky is that there are various versions of ID3 tags: ID3v1 only allowed a few, very short tags. ID3v2 allowed lots more, variable-length tags. And then there are different versions of the ID3v2 standard, to boot! Different media players can read different types of ID3 tags (and not read others, if you happen to get really unlucky!)
And to pile on the confusion, whilst FLAC files are supposed to be tagged with Vorbis tags, they can simultaneously store ID3 tags… and when a single FLAC files stores both types of tag, it's mostly pot-luck as to which ones a particular media player will choose to read and display.
Since CCDR only ever outputs FLAC files, it only tags files with the Vorbis tags. This makes it a well-behaved FLAC-using application, doing things “properly”. Unfortunately, those media players or other tools that are coded only to work with ID3 tags will therefore regard your files as completely un-tagged. But that's their problem, not yours (and is easily rectified by getting a better media player!)
8.0 What is the track offset I'm asked to supply?
Well, first: it's optional to supply a track offset.
If you do provide one, though, it is simply added (or subtracted) to the track number actually recorded on the CD.
As an example: Leoš Janáček's opera Jenůfa is supplied (in my Mackerras recording from 1983) on 2 CDs. CD 1 consists of 13 tracks, CD 2 has another 15 -of which the last is actually the standalone overture Žarlivost, and so not technically part of the opera at all.
When I rip the first CD, everything is fine: all 13 tracks belong to the opera and start from track 1, incrementing steadily to track 13. For ripping this CD, there is no need to supply a track offset at all.
But when I rip the second CD, I don't want its first track to be numbered '1', but '14', since it's the 14th track of the opera, regardless of being the first track of the second CD. When I rip this CD, therefore, I will ask for a track offset of 13. CCDR will then add that number to the physical track number, and thus physical track 1 will become ripped track 14. Physical track 2 will similarly become ripped track 15 and so on: basically, all tracks on the second CD will have their physical track numbers augmented by '+13', the supplied track offset number.
However, only 14 of the 15 tracks on this second CD actually belong to the opera. The 15th is a standalone overture derived from it. It shouldn't be included in the Jenůfa “album”, but be stored separately and numbered uniquely, too.
So, in fact, when I rip the second CD of the set, I would choose to supply a track range of 1-14 to rip, as well as a track offset of 13. That then gets all of Jenůfa ripped correctly, as one 'work' and with continually-ascending track numbers from 1 to 27.
I'd then perform a second rip of the second CD, specifying to rip only the last track on that CD (track 15), but supplying a track offset of -14 (i.e., negative 14). As before, CCDR just adds the physical track number to the supplied track offset, and since 15 + -14 = 1, this one-track rip to a work called Žarlivost will become track number 1 of a brand-new 'album'.
In short, physical track number + offset = ripped track number. And we can play with this equation with both positive and negative numbers supplied as the offset to either join tracks from multiple CDs into one work, or to take just part of a single CD and declare it to be a work of its own whose tracks correctly start at '1'.
Leaving the offset blank (i.e., just pressing Enter) is the same as typing in an offset of zero: both mean “I am happy to have the physical CD's track number become the ripped track's track number.
9.0 What's the 'only rip part of a CD' all about?
CDs often contain many separate works on the one physical disk. For example, it's quite common to see Beethoven symphonies 'paired' on a CD, so you'll get Symphony No. 1 and 2 on the one CD.
The fact that the two works are on one CD is irrelevant though, when it comes to digitizing the music: you will want Symphony No. 1 and Symphony No. 2 ripped as entirely separate works, no matter that they came supplied on the same medium.
Partial disk ripping gives you the chance to separate out the multiple works you find on a single CD. You can rip a single track, for example, simply by typing in a specific track number. Type 8, for example, and only the 8th track on a CD will be ripped. If you want to rip multiple contiguous tracks, but not the entire CD, simply supply a range of tracks when prompted, such as 5-8.
When typing a range, don't put any spaces in. Just separate the first and last tracks with a minus sign/hyphen.
Unfortunately, we can't rip multiple, non-contiguous tracks (so typing something like “4,7,11” would generate an error, for example).
10.0 What are CCDR's software dependencies?
Classical CD Ripper requires the following applications to be installed before it will work:
-
cdparanoia
-
flac
-
ffmpeg
-
awk
-
lssci
-
wget
-
grep
-
cdrecord (or wodim, depending on your distro).
Many of those are standard parts of any Linux installation and I'd be surprised if they weren't already present (awk, grep and so on). But if any of them are not present when you first run CCDR, you will be told. It's then up to you to install the particular applications using whatever tools your distro gives you. For example, to install ffmpeg on OpenSuse 15, you type sudo zypper install ffmpeg. On Ubuntu, it would be sudo apt install ffmpeg, and so on.
11.0 What Linux Distros does CCDR run on?
Like all my software, CCDR has been tested on a wide variety of distros. Basically, if the distro appears in the top-ten list on the Distrowatch league table, I will consider testing on it, provided only that it's a 'standalone distro' and not merely based on another that I already test on. Thus, at the time of writing, Pop_OS! is a top-ten distro, but since it's based on Ubuntu, and I already test on Ubuntu, I don't separately test on Pop_OS! The rule is not always strictly enforced, though! Linux Mint is also Ubuntu-based, but it's distinct enough and popular enough that I felt it important to be separately tested (in the same way that I separately test Ubuntu itself, even though you could argue it's merely 'Debian-based'!
As of March 2021, CCDR has been verified to run correctly on the (at the time) latest versions of:
- Fedora
- Ubuntu
- Manjaro
- OpenSuse
- Solus
- MX
- Endeavour OS
- Debian
- Linux Mint
- Raspbian
However, CCDR was originally developed to run on OpenSuse 15.0, Ubuntu 18.04 and Fedora 29, so it should work on any vaguely-current version of any of those distros.
The short answer to the question is, therefore, that it should work on pretty much any distro, but if it fails to do so on a specific one, please email me at [email protected] with full details about your O/S of choice and I'll see what I can do about it.
12.0 Why don't you install the software dependencies automatically?
Because I don't want totake control over your PC! CCDR does try to detect what distro you're using and will use that knowledge to suggest a one-line command that should install all the necessary software -but doing those installations automatically would mean CCDR would be in charge, rather than you. I generally don't think that's a good idea.
13.0 What use are the hashes?
Well, first thing to say is that you don't have to output the hashes if you don't want to. But if you do, they give you a value which basically sums up the audio content of the track involved. I stress “audio content”, because the hash number calculated for a track will not change just because you tag it or add a bit of CD cover art to it.
Proof:
hjr@britten:~> cd Music/Belshazzar\'s\ Feast/
hjr@britten:~/Music/Belshazzar's Feast> ls
hashes.txt track8.flac
hjr@britten:~/Music/Belshazzar's Feast> cat hashes.txt
track8.flac -> MD5=9a9c18e3482a1e6c501e4618eebb3436
This shows you I've ripped track 8 of a CD and it has a hash value of “9a9c…”. Now, let me modify the file:
hjr@britten:~/Music/Belshazzar's Feast> id3v2 -a "Benjamin Britten" track8.flac
That means I've just set the Artist tag for that track to “Benjamin Britten” (and yes, I've used ID3 tags for these examples, which is something you definitely shouldn't be doing yourself, but it's less verbose than doing it properly with metaflac and therefore makes for easier reading here). Now:
hjr@britten:~/Music/Belshazzar's Feast> ffmpeg -i track8.flac -map 0:a -f md5 -
That's me calculating the MD5 hash for the track in question. A lot of output is generated, embedded within which is:
ffmpeg version 3.4.4 Copyright (c) 2000-2018 the FFmpeg developers
Metadata:
encoder : Lavc57.107.100 pcm_s16le
MD5=9a9c18e3482a1e6c501e4618eebb3436
So, the MD5 hash is still “9a9c….”, as before. One final test:
hjr@britten:~/Music/Belshazzar's Feast> id3v2 -a "William Walton" track8.flac
This time, I'm setting the Artist tag back to “William Walton”, and the effect on the MD5 hash is:
hjr@britten:~/Music/Belshazzar's Feast> ffmpeg -i track8.flac -map 0:a -f md5 -
Metadata:
encoder : Lavc57.107.100 pcm_s16le
MD5=9a9c18e3482a1e6c501e4618eebb3436
So the hash remains invariant, regardless of what you do to the metadata within the file. That means the MD5 hash is a computation based purely on the music signal within a file and nothing else. Accordingly, you could rip the same CD on a different PC with a completely different CD or DVD drive -if the hash on that PC matches the value you got when you ripped it on the first, you can be confident that the audio signal for a track is not being altered depending on which PC or CD/DVD drive is doing the ripping -and that means you can be reasonably confident that your rip is a true and faithful replica of the audio supplied on the original CD.
14.0 What are the weird symbols shown when ripping?
Those come from Cdparanoia, the ripping engine, and a full description of them can be found on Cdparanoia's home page. The brief version is, however, that you want to see : -) whilst a track is being ripped -it means no error was detected during the rip. You also want to see :^D when ripping a track has finished: again, it means 'no errors'.
Apart from those 'smileys', you also see a display of track-ripping progress:

The area between the two square brackets indicate track progress: if you see X, * or ! in that area of the display, it means Cdparanoia detected a scratch or other problem when reading that part of a track. That's not good, though Cdparanoia will attempt to correct or read-around the problem. A lot of times, it will be successful in doing so.
In the screenshot above, however, you see what you want to see: nothing except a '>' symbol indicating progress!
15.0 I'd like CCDR to do something different...
All feature requests (or bug reports, come to that) are welcome. Just email me, Howard Rogers, at [email protected].