0.0 What is AMP?
AMP is a console-based, optionally-randomising, whole-composition, trackless, optionally-scrobbling, classical music-oriented, gapless FLAC player, with optional support for a database and its related search and record-keeping capabilities
Which is a bit of a mouthful of a sentence, so... Taking that apart in no particular order:
- AMP runs on the command-line without a fancy GUI
- It plays FLACs and only FLACs
- It plays FLACs a folder-at-a-time, and it is assumed that a folder of music=a composition
- Where movements of a work are supposed to flow seamlessly into each other without a break, AMP will do that
- It will not display progress through a 'track' or allow interaction with individual tracks: you play a symphony, you listen to the symphony, not four 'tracks', individually selectable or repeatable
- It can, if so configured, report what it has been asked to play to Last.fm, thus building up a remote history of listening (this is called 'scrobbling')
- It will randomly select a folder to play, if asked...
- ...Though it can also play the contents of a specific, non-random folder if told to
- It can optionally keep records in a local database of what has been played and what is available to play to determine what it should randomly play next
- Reports from a database, if it's been used at all, are the equivalent of local scrobbling (i.e., making a record in a locally-stored database, not Last.fm's cloud-based one)
- Though AMP's main features are all designed around playing classical music, it can play any music presented to it in FLAC form, though appropriate tagging of ARTIST, TITLE and GENRE tags would be minimally required for it to work well with such music files.
Other features worth mentioning: AMP can play high-resolution FLACs ripped from SACDs or other high-definition audio sources. It will record what it plays in a database (if one is available) so that listening habits can be measured and used to influence what new things to play. It is open source. It is provided in the form of an 'orchestrating' shell script: the actual software that does all the real work is, mostly, sqlite and ffmpeg. AMP merely coordinates and organises these other software packages into doing its bidding. I also know of no other music player in existence that will allow you to ask it to play compositions in such a way as to even-up the amount of music played by different composers over time, so that your listening experiences are, and always remain, broad and diverse: but AMP does do that.
1.0 What is the difference between Fast and Full scanning when populating a database?
Both scan modes populate a table called "Libraryartists" (one row per discovered composer) and "Albums" (one row per discovered album, but they achieve this outcome in two different ways.
The fast scan finds folders containing FLAC files within a 'directory tree' and then reads the metadata from the first FLAC file found in each folder only. The full scan similarly finds all folders containing FLACs, but reads every FLAC files' metadata, populating an intermediate table called "tracks" as it does so.
The difference is that the fast scan is obviously much quicker. Imagine a folder containing 45 FLAC files, comprising all the tracks associated with a 5 Act opera. The fast scan only reads one file before declaring it has found 'Giuseppe Verdi' to be the composer and 'Otello' to be the opera. The full scan reads all 45 files, creating 45 rows in the tracks table, each saying 'Giuseppe Verdi, Otello'.
At the end of its work, the full scan creates the libraryartists and albums tables as distinct (i.e., unique) selections out of the tracks table.
Both types of scan therefore ending up creating the same pair of tables that AMP then goes on to use, except that the fast scan does it much more quickly.
2.0 When I do a fast scan, I'm told I have 400 albums belonging to 114 unique composers. When I do a full scan, I get different numbers. Why?
To start with, read the reply to question 1. Once you understand that full scans read metadata from every FLAC file, whereas fast scans read metadata from only the first FLAC file, in a folder, it then becomes obvious why the two scans could result in different outcomes.
Imagine, for example, a symphony, made up of 4 tracks. The metadata for tracks 1, 2 and 3 are identical: Beethoven and Symphony No. 5 (Bernstein - 1972). For some reason, however, track 4 was tagged as Beethoven and Symphony No. 5 (Bernstein - 1963). (i.e., the recording year was entered differently for the fourth track alone).
The fast scan only reads track 1's metadata, and so will declare there is one composer and one album: the 1972 recording of the symphony.
The full scan will read all four tracks' metadata and will therefore see one composer but two albums, because the album name in track 4 is subtly different from that contained in the other 3 files. Therefore, the scan will declare that is one composer and two albums.
Whenever the fast and full scans produce different numbers for composers or albums, therefore, it almost always points to a tagging/metadata error somewhere in your music collection. Tracking such errors down is tricky, but can be done with a tool such as the DB Browser for SQLite and direct access to the AMP database tables -but you will need to be good at SQL and database management to achieve much in that regard, I'm afraid.
Fortunately, number discrepancies between the two scan modes generally do not affect functionality. In both example scans described above, the same physical folder is recorded for the album(s) found by either scan mode. The full scan will, for example, find that album 1 lives in a folder called /music/Symphony No. 5 (Bernstein - 1972) and album 2 lives in a folder also called /music/Symphony No. 5 (Bernstein - 1972): though the metadata for the two albums is different, the physical folder 'they' live in is the same in both cases. AMP's playback function always consists of moving to a physical folder and playing all FLAC files found there, regardless of their metadata. So the different number of albums returned by the full scan doesn't prevent the entire symphony being played afterwards.
3.0 Can AMP play non-FLAC files?
No. It only searches for and plays FLAC files. It simply wasn't written with the intention of ever playing any other type of music file. Will it ever be able to play non-FLAC files? No. I believe in free, open source and non-proprietary audio codecs that lose none of the original audio signal. FLAC is about the only audio codec that meets all those criteria without ambiguity. Apples' lossless codec is now in the public domain, but it didn't start that way. APE is free of charge, but it isn't open source and has a very dodgy license (which is why Debian, and hence Ubuntu, tend not to include it in their standard repositories). Lossless WMA is proprietary and patent-encumbered Microsoft. Codecs like OGG and MP3 are, of course, lossy and thus not suitable for use by anyone that care about the quality of the music they listen to.
4.0 Why do I need a database?
You don't. The default mode of operation is, in fact, not to use a database at all. Point AMP at a folder of music files (with the --musicdir parameter) or physically move to such a directory (with your operating system's cd command) and it will play what it finds there. Point it to a folder that doesn't itself contain music files, but contains sub-folders and sub-sub-folders which do, and it will randomly select one of those folders to play its contents. No database is necessary in any of these scenarios.
The trouble with the last scenario, however, is that it involves a physical trawl through the folders and sub-folders to find FLAC files before it decides to play anything. In a large music collection, that physical 'walk' through your folder structure will take time -and that means there will be an appreciable delay before randomised playback begins.
There is another problem with the 'physical walk' approach, too: if you have a huge Mozart collection, a large Handel collection and a tiny Alan Rawsthorne collection, the chances of the randomised selection ever being of something that Rawsthorne wrote is equally tiny. In other words, the relative sizes of your composers' music contribution to your music collection affects the probability that they will be selected for random play. Which means 'physical walk' randomisation isn't very random after all!
The use of a database fixes both these problems. Instead of (say) 50,000 physical FLAC files to walk through, stored in (say) 8,000 different folders, AMP with a database now has a single table containing 8,000 rows to search through. That takes sub-second time to search, so the delay before playback is massively reduced.
Secondly, AMP's database is comprised of two fundamental tables: composers (called 'libraryartists') and recordings (called 'albums'). Each composer gets 1 row in the composers table, no matter how many recordings are attributable to them. That means each composer is just as important as any other -and the probability of selecting any one of them randomly is thus equalised. Having selected a composer at random, AMP then randomly selects from recordings belonging to that composer -but the choice of composer in the first place means true randomisation of whose music to play has already taken place.
Using a database with AMP is therefore encouraged if you ever want to do randomised play, because the playback will start more quickly and will be the result of 'true' randomisation, unaffected by the quantity of music attributed to any given composer.
5.0 Can I make/prevent AMP selecting a particular composer's work?
Yes to both the 'make' and 'prevent' bits of the question!
First, preventing plays by a specific composer. If you create a text file called excludes.txt in the $HOME/.local/config/amp folder, then AMP will always read that and incorporate it into its randomisation process as composers whose work should not be selected for playback. The text file must contain one composer's name per line -and the composers' names should be spelled out exactly as they are used when you tagged your music files.
That is, if excludes.txt says 'Wolfgang Mozart' and you tagged all your Mozart operas as being composed by 'Mozart, W', then the exclude will not take effect. Only when the exclude matches exactly what is in the ARTIST tag will it work.
Secondly, making AMP play something by a specific composer: From version 1.09 onwards, you may additionally supply a --composer=xxxx runtime switch when invoking AMP. The value of the 'xxxx' bit should match all or a part of a composer's name. For example --composer=britten will make AMP only find compositions by Benjamin Britten; --composer=william will make it find works by any composer whose name has 'William' in it somewhere (so William Herschel, William Walton and even John Williams will be available to be selected at random).
The search term is case insensitive. --composer=britten works exactly the same as --composer=BRITTEN or even --composer=bRiTtEn.
Compound names should be wrapped in double quotes, so --composer=Benjamin Britten won't work, but --composer="Benjamin Britten" will. The double-quotes make the space in the name 'invisible' as far as AMP's error-checking code is concerned.
Note that if you specify to play something by a composer with the --composer switch then the excludes.txt is ignored. In a sense, the runtime switch over-rides the excludes.txt.
Of course, if you use AMP in local mode (that is, you cd to a specific folder of music files), AMP will play whatever it finds there, regardless of excludes or any other considerations. So, in this sense, you've always been able to force AMP to play Britten's Peter Grimes: cd /"Peter Grimes", amp would do the job!
6.0 Can I make/prevent AMP selecting a particular genre of music?
From version 1.09 onwards, yes you can. You can supply a --genre=xxxx runtime switch when invoking AMP. The value of the 'xxxx' bit there needs to match one of the genres you've tagged your music with (or part of the tag). If you've tagged your music as 'Symphony', for example, it's no good then saying --genre=Symphonic. Nothing will be found in the database that matches 'Symphonic', so nothing will be selected for playing: you'll get an error message telling you to re-think your runtime switch settings instead.
The value you supply can be partial, though. For example, I have music tagged as 'Film - Theatre - Radio'. That's a bit of a mouthful to type (and I can never remember the order of the three components, anyway!) But if I typed --genre=radio, that would be sufficient to get a match. AMP basically takes the supplied value and wraps it in 'something'... so it ends up searching for something-radio-something, and that's enough for the first 'something' to cover the actual 'Film - Theatre' found in my music tags. Similarly, a search for --genre=Symph would be fine for finding 'Symphonic' or 'Symphony', if you've been less than consistent in your use of tags in the past!
Note that the supplied value does not need to match on case. Searching for 'radio' or RAdiO' or 'RADIO' will all work equally well.
You cannot supply compound genres: that is, if you said --genre=concerto,opera in the hope of randomly selecting either a concerto or an opera, that won't work: AMP will be looking for a piece of music that is literally tagged 'concerto,opera' and since there won't be any music tagged that way (we hope!), it will again fail to find anything that matches and warn you.
7.0 Can I make/prevent AMP selecting music conducted by a particular conductor or performed by a particular orchestra?
Yes. There are two separate switches to deal with this sort of thing, both introduced in AMP Version 1.09.
First, remember that this site's tagging guides recommend that you put the list of performers making a particular recording into the COMMENT tag and then one of those performers -the one that makes this recording most distinguishable from any other- into the PERFORMER tag. Hence, you might enter the COMMENT for a recording of Beethoven's Symphony No. 5 as 'Herbert von Karajan, Berlin Philharmonic Orchestra' -and, in that case, "Herbert von Karajan" might also be written into the music files' PERFORMER tag on its own.
In that situation, you can now supply either a --performer=xxxxx or --comment=xxxxx tag to match those tags as the mood suits. If you wanted to hear something definitely conducted by Karajan, for example, then you'd perhaps supply --performer=karajan as a runtime switch. If you wanted to hear Maria Callas singing, regardless of who was conducting here, you might say --comment=callas
As with the composer and genre run-time switches mentioned in FAQ 5 and 6 above, AMP does a wildcard match on the argument you supply, so that 'karajan' is enough to match a tag that's actually set to 'Herbert von Karajan'. It's also a case-insensitive match, so 'kArAjAn' will match 'Herbert von Karajan' perfectly well.
Note that the --comment switch is the lowest in the hierarchy of random-override switches, with --performer next lowest in hierarchy.That means you can't use either of these switches together or in combination with the --composer or --genre switches. If you do, all but one of them will be ignored, in their order of precedence, which runs as follows:
- Artist
- Genre
- Performer
- Comment
So if you supply --composer and --comment, the comment switch will be silently ignored and only the --composer one will have any effect. Similarly, if you supplied both --performer and --comment switches, only the performer one would affect what AMP actually played. The other would just fail to affect anything.
You cannot, therefore, say 'play me something with Karajan conducting and Callas singing' by supplying --performer=karajan and --comment=callas switches. It's one or the other, never both.
As with all the override switches, case is insensitive (so Callas can be found with --comment=CALLAS, --comment=callas or --comment=CaLlAs equally well). Also as with the other override switches, the value you supply will be wild-carded on the 'outside', so that 'cal' would match 'callas' or 'John Calthorpe', but would not match a comment that contained the text 'John C. Althorpe'.
8.0 Where is the AMP database stored and what is it called?
You have to ask for an AMP database to be created with the --createdb runtime option: at that time, if you also specify the --dbname=<something> runtime option, you get to choose the name of the database: it will be whatever name you specify after the equals sign of the '--dbname=' parameter. If you don't specify a name, it will be called "music" by default.
If you do want to specify a name, you should stick to single-word names without spaces (though, if you insist on spaces, you can do so by wrapping the whole name in double quotes. Thus --dbname="My music database" would be valid). Names without spaces do not need to be wrapped in double quotes.
In all cases, whether the default name or a customised name is specified, the database ends up being stored as a single file in the $HOME/.local/share/amp folder. Note the period/full-stop before the 'local' part of the path: it means the 'local' folder is hidden, and you'll need to turn on the 'show hidden files and folders' feature of your file manager to see it.
Also in all cases, the extension ".db" is added to the database name. So the default database file is called 'music.db', and if you said --dbname=main, the database file would be called 'main.db'.
9.0 What type of database does AMP use if one is created?
AMP uses a SQLite3 database. That means the database file (see Question 7 above) can be opened by any SQLite3-compatible client (such as DB Browser for SQLite) or at the command line with the command sqlite3.
The database is very simple: there are no indexes of foreign keys created and there are only a maximum of four tables involved (and usually only three): libraryartists, albums, plays and (optionally) tracks. The tracks table will only exist after a full-scan; the other three exist whether you do a full or fast-scan.
The libraryartists and albums tables are only ever read, never updated, except in the case of a new --refreshdb operation being run, in which case they are completely wiped and re-created essentially from scratch. The plays table is inserted into every time some music is played when database use has been specified. It records when an album was played, and what artist, genre and performer pertain to that album. Note that it records album plays, not track plays. So if you play a 4 movement Beethoven symphony and a 65-track Verdi opera, both plays will add one row each to the plays table.
Even with a large music collection played frequently, the database will be very small: in the order of a few tens of megabytes (MB).
10.0 AMP doesn't display what tracks I'm listening to. Can it?
No. First of all, it's a side-effect of the fact that AMP performs gapless playback (i.e., without introducing additional pauses in playback as it switches from playing one track to the next). To do this, it concatenates or joins all the tracks in a folder into a single 'virtual' FLAC, which is then played. At that point, AMP is playing a single virtual file, not separate tracks, so it cannot report on specific tracks, since it isn't aware of their existence.
Secondly, AMP is designed to be a classical music player and a deliberate design decision was made when writing it that, really, classical music listeners shouldn't really need or want to see "tracks": they listen to concertos, or symphonies, or operas. They don't (or shouldn't, really!) be listening to "bits" of a concerto, or specific "movements" of a symphony. If you agree that this paradigm has any validity at all, then it is apparent that displaying track information in a classical music setting would be rather inappropriate!
It's also why AMP only records whole-album plays in the 'plays' table in its database (assuming you use one): "bits" of compositions simply don't fly in the world of classical music. It's either the whole composition or nothing!
Anyway: whether it's appropriate or not is not the main consideration. The over-riding requirement to do gapless playback means that it physically isn't possible for AMP to report on specific tracks.
11.0 What are 'local' and 'remote' modes?
AMP can be run in two ways. If you cd to a folder containing FLAC files and then type 'amp', AMP will launch and play whatever FLAC files it finds in the folder it's launched from. There is no randomisation or selectivity involved: it simply plays all the FLACs it finds in its current working folder sequentially and completely. That is termed running AMP in local mode.
Alternatively, you can run AMP without first cd'ing to a folder of FLACs and instead point AMP to that folder by using the --musicdir=</path/to/FLACs> run-time parameter. AMP is therefore not being launched from 'within' a folder of music files, but is being pointed to them from elsewhere. Hence, this is termed running AMP in remote mode.
Functionally, there's not a lot of difference: even in remote mode, if pointed to a specific folder containing FLACs, AMP will play all the FLACs contained in that folder, sequentially and completely.
The difference between the two modes is that remote mode can be invoked by pointing AMP not to a folder of FLACs, but to a folder that contains sub-folders and sub-sub-folders that in turn contain FLACs. When that happens, AMP will search within the folder structure to find any FLACs it can and then select one set of them to play back randomly.
Remote mode can permit random playback, in other words, where local mode cannot. Remote mode doesn't mandate randomness, however. It only implies randomness if the --musicdir folder specified at run-time does not itself contain FLACs.
As an example: imagine you had a folder called /music that contained a sub-folders called /Bach, and within /Bach you had a folder called /Brandenburg Concertos and another called /Goldberg Variations -and within those sub-folders, you had FLACs of the Brandenburgs and Goldbergs. There are then three scenarios:
- You could type cd /music/Bach/Goldbergs and then amp and you would be running AMP in local mode, playing the Goldberg Variations completely and in sequence.
- Or you could type amp --musicdir=/music/Bach/Goldbergs. You'd then be running AMP in remote mode, playing the Goldberg Variations completely and in sequence, but from a specific folder directly containing FLAC files.
- Or you could type amp --musicdir=/music. Now you'd be running AMP in remote mode and getting it to randomly play either the Brandenburg Concertos completely and in sequence or the Goldberg Variations completely and in sequence. The pointing to a folder that itself does not contain FLAC, but which is the 'root' of a folder structure that does have FLACs in it somewhere triggers randomised 'remote' operation.
In scenario 3, you wouldn't know which of the compositions would be selected for playback, but AMP would choose for you. Having made its choice, however, it plays back whatever it has chosen completely and in sequence. It doesn't randomise the order of tracks to playback, in other words; only the choice of which album to play is randomised.
12.0 What is the point of randomised playback?
Only that with a large music collection, you will often tend to keep playing 'old familiars' over and over again. It becomes harder to dig through the more obscure corners of your collection the larger it grows (in my experience, anyway). By randomising which compositions to play, AMP helps you play the more obscure repertoire and not merely keep playing the old favourites over and over again.
However, it's entirely optional. If you don't want randomised playback, you don't have to have it. See question 11: in 2 of the 3 scenarios discussed there, randomised playback doesn't happen.
13.0 What is Scrobbling and why would I want to do it?
Scrobbling is the name given to the process of sending details to a database of the music you've been listening to. Usually, that database lives in 'the cloud', meaning it's provided by someone over an Internet connection. The usual 'someone' providing this service is Last.fm.
Though Last.fm is strongly geared towards non-classical music listeners, it will accept 'scrobbles' (i.e., listening reports) from anyone who is a member, no matter what music they listen to.
Last.fm's main goal is to get a 'community' of music listeners sharing their music listening habits -and watching the adverts they serve as they do so! But there's nothing to stop you simply using it to record what you listen to over time. It's a handy way to find out who your favourite composers and pieces are, and to spot when you're maybe over-playing one composer and under-playing others.
I've use it since 2008 to record my 'listens' and in consequence am aware of how prone I am to over-playing Britten and Bach and under-playing the likes of Mahler or Schubert. Whether you let such knowledge alter or affect your listening habits is up to you, of course -but I've found it a useful prod to getting me to listen to less-mainstream music and thus to broaden the pool of composers whose music I listen to.
Getting AMP to scrobble, however, is entirely optional. If you're not interested in doing so, just provide a --noscrobble run-time parameter any time you run AMP.
If you I want to scrobble, you need first to create a Last.fm account (which costs nothing apart from parting with an email address -and I don't think I've ever received email from them in over 13 years of membership!). You then need to download the amp-scrobbler.sh script and install it as per the instructions in Section 4 of the main article.
14.0 Can I have several databases?
There is no fundamental limit to the number of databases you can create and use with AMP. You could conceivably have separate databases for 'Bach', 'Mozart', Beethoven' and 'Others', each one pointed to specific directories, provided only that one directory doesn't imply any of the others (in which case, the databases will simply duplicate their content, somewhat pointlessly). For example, suppose you have this physical folder structure
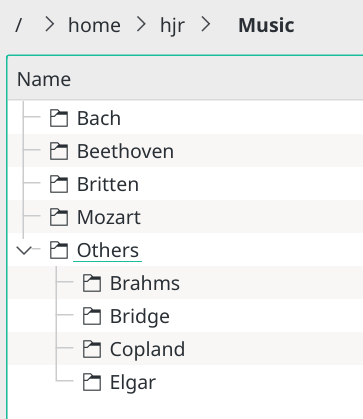
Then it would be possible to create the 4 databases mentioned -but you'd never end up randomly selecting any Britten to play, because his folders aren't covered by any of the proposed databases. But if I also created a database called 'allmusic' that pointed to /home/hjr/music, then I'd have a database that contained Bach, Beethoven, Mozart, Others and Britten, plus individual databases for Bach, Beethoven, Mozart and Others.
I could then do --usedb --dbname=allmusic and possibly get Britten's music selected at random. Or I could do --usedb --dbname=Mozart and get a random selection of something Mozart had written: I'd have great flexibility in directing AMP's randomness, in other words.
So, if you have your music folders organised appropriately, there's nothing to stop you having as many separate databases as you feel you need to match your music listening needs and moods.
15.0 You don't show Album Art: how do I visually know what is playing?
Actually, from version 1.05 and above, AMP does show Album Art if ImageMagick is installed and you don't explicitly ask not to see album art.
Let me now unpick that rather convoluted sentence!
First: ImageMagick is a graphical toolkit which is widely used for image display and manipulation on many operating systems, but it's especially common to see pre-installed on Linux distros. If it is installed, then you're half-way to having album art displayed by AMP. Note, however, that if ImageMagick is not installed for some reason then AMP won't prompt for it to be installed. Fundamentally, AMP was designed to be a command-line only player, so it doesn't really care about album art, so if it finds ImageMagick missing, it just silently ignores the point.
Second: there is a run-time switch that you can use to switch off the display of album art: --noart. If you add that to the command line when launching AMP, then even if ImageMagick is installed, no album art will be displayed.
Without that switch, however, if ImageMagick is installed, then album art from the playing music will be displayed in a separate window that can be moved, resized or closed as any normal program window on your desktop would be. AMP always displays the album art at 900x900 pixel resolution, no matter what the original album art size was originally.
Note that if you close the album art display window, you cannot re-open it. The next piece of music AMP plays will open a new window and display the album art from that new piece of music, but the original can never be re-opened.
16.0 Why can't I pause the music?
Because you are listening to classical music and you shouldn't be doing that! OK, that's being a bit school-ma'am-ish, so let's start by saying that I deliberately didn't want to festoon AMP with volume and play-pause-rewind-fast-forward controls because I think and believe that classical music is better listened as its composers probably intended it should be: start at the beginning, listen carefully throughout, stop at the end. The idea of pausing music playback certainly suits our distracted, interruped life-styles today, of course... but it's not what classical music is supposed to be about!
If you want to pause the music, you simply have to press Ctrl+C, though this means that AMP playback will actually be terminated. Ctrl+C really will kill playback, with no possibility of resumption from where you left off (you can always re-run AMP, of course, but it will play from the start again). If you Ctrl+C, too, then no scrobbling is performed of what you've listened to up to that point, nor is any entry made in any database you might be using. It will be as if you walked out of the concert half-way through the first movement: that doesn't count as having listened to anything at all!
17.0 AMP stops playing a folder after some time, without playing everything. Why?
There is one known reasons why this happens: your file names contain two dots, full-stops or period marks in succession. This filename, for example, will play just fine:
09 - Ebben. ne andro lontana-preview.flac
But this one will not:
09 - Ebben... ne andro lontana-preview.flac
The use of even two full-stops in sequence is, in fact, enough to kill AMP.
Unfortunately, of course, multiple full-stops in succession is not unheard of: they are often used as an 'ellipsis', so you will commonly see them used in opera tracks, where one character stops singing and another picks up the dramatic pace. They will break the audio engine that AMP relies on, unfortunately.
There are three possible workarounds.
First: Don't use three full stops, but use the proper ellipsis character (Unicode character 2026). This file name uses that character, for example, and does not break AMP:
09 - Ebben… ne andro lontana-preview.flac
Now, you will probably be hard-pressed to spot the difference between that file name and the one listed above it. They both have 'three dots' in their name. But in this second case, it's actually a single character which simply has the form of three dots. In the earlier case, it was genuinely three separate full-stops. Typing an ellipsis on Linux is not hard: it's just <compose key>+two full stops: … (which produces three dots, even though you only type two of them!). It's not too hard on Windows, either: ALt+0133. So if you can get into the habit of tagging your files using the proper ellipsis character, and thus getting their physical file names to match also using the single ellipsis, you'll be fine.
Second: If, like me, you already have lots of albums tagged up using three separate dots instead of the proper ellipsis character, then re-tagging them all is not going to be an attractive proposition. You could, however, without much pain, run CAO over the files. My 'Composition-At-Once' utility turns a bunch of FLAC files in a folder into a single 'super-FLAC' which contains within it all the information belonging to the individual files. As part of the way it works, however, CAO strips out two- or three-dots in sequence. It replaces them with an ellipsis (a proper one) instead.
Third: If turning all your per-track FLACs into single super-FLACs sounds a bit drastic, but you like the sound of automatic replacement of multiple dots with a proper ellipsis character, then you can run my Auto-Ellipsis Script (AES) against your FLAC files. It will scan all the files in a folder, replace any two- or three-dot characters it finds in both file name and metadata tags with a proper ellipsis character... and not otherwise touch your per-track FLACs.
Fourth: If you tag your music files using my own CCDT utility, that will automatically spot when two or three full-stops are mentioned in track names and will automatically replace them with proper ellipsis characters wherever they occur. If you rip your CDs in the first place with my own CCDR utility, that too will auto-replace multiple full-stops for you, preventing this from being a problem in the first place.
So yes: AMP playback of a folder-full of music will be killed at the point where it encounters the first file name containing 2 or more full stops in sequence. You either manually rename files to remove the multiple dots, or replace them automatically with either the CAO or AES utilities, or use the CCDR and CDDT utilities to rip and tag your music files, which will prevent the 'fatal dots' from ever getting into your file names from the outset.
18.0 AMP is saying I'm playing 16* tracks. What is the '*' doing there?
Since day 1, AMP has been able to count the number of FLAC files stored within whatever folder it's playing. But since version 1.06, AMP has been able additionally to work out the number of 'virtual' tracks are contained within a folder, even though only one physical FLAC file is present.
A 'virtual track' means that the physical FLAC contains within it an embedded cuesheet, describing where parts of the physical FLAC file begin and end. For example, take this folder:
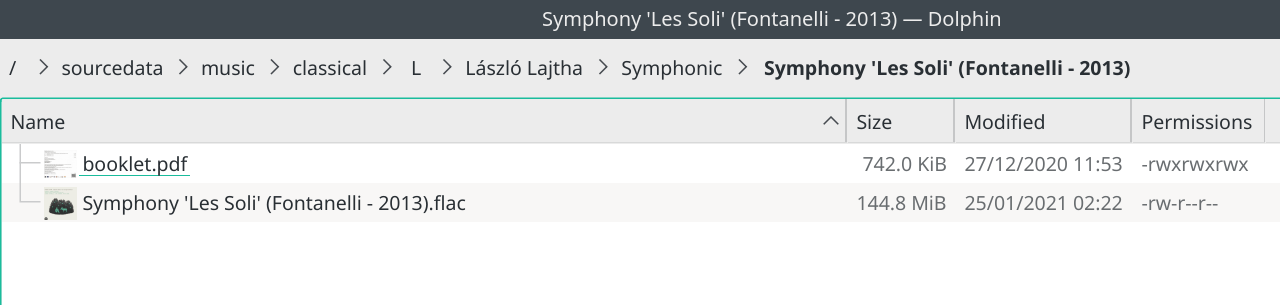
It contains a single FLAC file (plus a booklet PDF). So there is physically only a single FLAC. In all versions of AMP before 1.06, this would have displayed as 'Playing 1 track'.
But if we look inside this single FLAC file, we see this:

That's an embedded cuesheet, and it shows that this single physical FLAC is really comprised of four different 'movements', each only labelled a 'TRACK' and -as an example, track number 4 starting to play 23 minutes 34-and-a-bit seconds into the playback of the physical file.
In other words, FLACs can be 'super-FLACs', and contain within them the instructions on how to play parts of themselves. Since version 1.06, AMP is smart enough to recognise an embedded cuesheet, read the number of 'tracks' mentioned within it, and display that as the number of tracks being played, rather than the single count of the physical FLAC file.
When AMP displays the number of 'virtual' tracks being played, rather than the number of physical FLAC files, it will display the number with an asterisk, so you know that you're dealing with virtual tracks not physical ones. Thus:
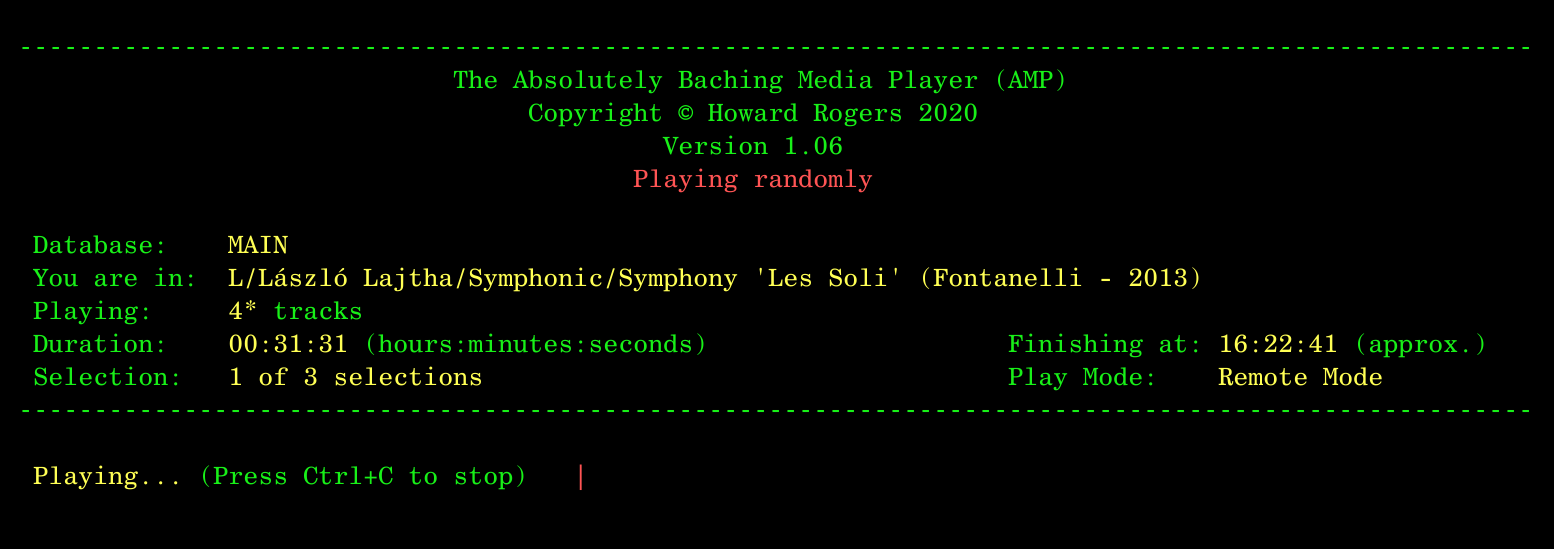
...AMP is correctly showing that 'Les Soli' is made up of four virtual tracks, found within the one physical file you've already seen displayed in my file manager above.
19.0 Why do I get told 'unable to select a composer randomly'?
When AMP is run with a back-end database, it stores details of everything it then plays. It uses this record to make sure that it doesn't select anything else by a composer it's already randomly selected, within a time period known as 'the time bar'. By default, the time bar is 6 hours, meaning that if (say) something by Benjamin Britten was selected for play at 9AM, nothing else by Britten could be played until at least 3PM. (If you were to go to a folder containing some Britten and invoke AMP in local, non-random mode, this time bar has no relevance: AMP will always play what you specifically tell it to play. We're talking here only about what happens when you point it at a folder full of folders of FLACs and ask AMP to pick something at random).
If you don't have many distinct composers in your music collection; and if the music pieces attributed to each composer are all quite short, it might be possible to randomly select something by all of them and have them all played by, say, 11AM. Any attempt to then re-run AMP at, say, 11.30AM will find that all potential composers have already been played within the past 6 hours -so no composers end up being select-able this second time round. (Frankly, you'd have to have very few composers in your collection for this to happen, but I suppose we have to document all possibilities, no matter how remote they might be in reality!)
The fix is to see what happens when lower the time bar. Running AMP with --timebar=0, for example, means that no hours need elapse before a composer is eligible to be selected again (so, basically, there's no time bar at all). You are allowed to supply any number between 0 and 9 for the timebar parameter. The lower the value supplied, the more likely it is that a composer will get randomly selected for plays multiple times a day. NB: In version 1.26 and above, the maximum permitted time bar was raised to 999 hours, so bars of up to (around) 4 days are now permitted.
Remember that AMP only records a 'play' when a piece of music has finished playing completely. So, if you start playing a Wagner opera at 9AM, that won't be recorded until it finishes around (say) 1.30PM. So Wagner's default timebar won't then be released until 7.30PM. In other words, Wagner's time bar won't lift at 3PM, just because you started playing him six hours before then. For the same sort of reason, if you interrupt the playback of a piece of music (by pressing Ctrl+C), no record of that music as a 'play' is made and therefore that composer is not subject to a time-bar at all.
If you still get no joy when the timebar has been set to 0, it's possible the database AMP is using has become corrupted for some reason. Running AMP with --dbname=<some value> --refresh may well fix that. Failing that, creating a whole new database (with --createdb --dbname=<new name>) should resolve the situation.
Other possible (and perhaps more obvious) reasons for the error message: if you specify --composer=Brittten, that is probably a mistake, because Benjamin Britten is spelled with only two t's, not three! Similarly, if you say --genre=Operra, AMP is unlikely to find any music files tagged with that particular mis-spelling of the word 'opera'! In other words, if you've specified either the --composer or --genre switches (from version 1.09 onwards), you may have supplied a value for one of the parameters that simply doesn't match what you've actually tagged your music as.
20.0 I ask for 99 selections and only get 1. What's up?
Since version 1.06, the --selections run-time parameter can only take a value from 1 to 9. If you supply a non-numeric value, or a numeric value outside those bounds, the default number of selections kicks in -and the default number is 1. However, from version 1.20 and up, the ability to ask for up to 99 selections is restored. Ask for more than 99 selections, however, and you'll get 1 as was previously the case when you exceed the bounds for that parameter.
21.0 What's the complete list of run-time switches?
It depends on version, but the latest version at the time of writing is 1.26, and the complete set of switches you can supply for that version are as follows:
| --noscrobble | If present, AMP will not submit your music plays to Last.fm, even if scrobbling has been installed and configured. A local record of what has played is always generated, however. | The default behaviour is to scrobble to last.fm, if the amp-scrobbler script is present and configured. |
| --musicdir=xxx | Points AMP to a hard drive folder location where music files can be found. | |
| --selections=x | Specifies the number of different plays AMP will attempt before seeking further input. Maximum 99, defaults to 1 | |
| --usedb=xxx | Instructs AMP to use a database to make its random selections more quickly, and to record a local copy of what music has been played. The switch's argument should be the name of the database that has previously been created. | Default name of the database if not specified is assumed to be 'music'. |
| --refreshdb | A special running mode for AMP: it won't attempt to play any music at all, but will instead scan a specified music directory for music files and store the results of its scan in the specified database | Requires --musicdir and --dbname parameters, so the program knows where to find files and in what database to store the results. |
| --createdb | Another special running mode for AMP: no music will be played, but a database structure will be created for future population (by --refreshdb and --dbname parameters) | Requires --dbname if a non-default database name is required (the default being 'music'). |
| --scanmode=xxx | Another special running mode for AMP: no music is played, but a music directory is scanned for content and a database is populated with the results. The switch's value can be fast or full. The default is fast. | Requires --dbname, otherwise the results will be written into the default database called 'music'. Also requires --musicdir so that the scan knows where to find music files |
| --dbname=xxx | Whenever AMP is instructed to use, create or refresh a database, it will assume that the database to use is called 'music', unless this parameter is supplied to tell it a different name. The parameter's values will be the name of the database created, refreshed or populated by a scan. | If absent for any command that needs to know the name of the database to use, refresh or store things in, "music" is assumed to be the default name. |
| --report | Another special running mode for AMP: no music is played, but a simple columnar report from the database's PLAYS table will be displayed, which can be scrolled through, up and down. | Requires the use of --dbname, otherwise AMP will assume that you're wanting a report of the PLAYS table in a database called 'music' |
| --noart | A switch which, if present, prevents the display of album art. If not supplied, AMP will attempt to extract the album art from the first FLAC found in a directory and display it in a 900x900 pixel window. | Note that if not present, album art can only be displayed if ImageMagick is installed -and if it's not installed, you will not be warned about it. |
| --timebar=x | A switch that takes a value of between 0 and 999. These are the number of hours during which a composer cannot be re-played if once played. Supplying a value of 0 switches this 'timebar' feature off: a composer can be re-selected at random immediately after having had one composition selected for play.
The default time bar is 6 hours, which is meant to stop the repeat-playing of the same composer over and over again within a short time window, without being too restrictive about it. |
The default timebar is 6 hours, so if Bach is played at 9AM, he cannot, by default, be played again until after 3PM.
Note that in versions prior to 1.26, the maximum allowed timebar was 9. Only in versions 1.26 and above was that was increased to a maximum of 999 (which is approx. 40 days). |
| --genre=xxx | An override that forces AMP's random music selection to only select works that have been tagged to be part of a particular genre. So --genre=choral would mean only choral works are played, no matter who wrote them or who's conducting or performing them. | Note that these four switches are mutually exclusive. If you specify more than one of them at a time, only one will actually take effect. The order of precedence (in descending order) is composer, genre, performer, comment. From version 1.12 onwards, you can specify both composer AND genre, however, and both will take effect. It's the only such combination of switches allowed, however -and both still work independently too, if you want to specify them individually.
So if you supply both the composer and performer switches, for example, only the composer one will actually work. Similarly, supply both a genre and a performer, only the genre will take effect. The switches do wildcard matching and are case-insensitive. |
| --composer=xxx | An override that forces AMP to select works by a particular composer. This does not respect the excludes.txt or the timebar. If Bach was played at 9AM and you say --composer=bach, something by Bach will be selected for the next play, no matter what time it is. | |
| --performer=xxx | An override that forces AMP to select works for play that are said to have a particular performer's name in the PERFORMER tag. That tag would usually have a conductor's name in it, but it might be a pianist or a leading soprano for works where that sort of tagging makes sense. Thus --performer=karajan would make AMP perform works conducted by Herbert von Karajan, so long as the word 'karajan' appeared in the PERFORMER tag somewhere. | |
| --comment=xxx | An override that forces to select works for play that have been tagged with a COMMENT tag that contains the supplied text in it somewhere. So, if you wanted to listen to any opera in which Maria Callas is singing, and provided you've tagged her somewhere in the COMMENT tag, you could now do a --comment=callas to get AMP to play things where Callas is listed as a singer somewhere in the COMMENT tag. | |
| --negates | Reverses the sense of the other overides, if present (has no effect otherwise). That is, if you say --performer=karajan, adding the --negate switch makes the sense of the selection become "performer must not be karajan". Similarly,--composer=britten --negate means play any composer you like so long as it's not Britten. | Introduced in version 1.10 and above. Only reverses of the genre, composer, performer and comment override switches. Alters the meaning of nothing else. |
| --artsize=xxx | If album art is displayed, accepts values of large, medium and small to determine the size of the display. Small is 300x300 pixels; medium is 600x600; large is 900x900. The default is 600x600 and applies if no artsize is specified at all or if it's supplied but with an invalid value. --artsize=frederick-dalrymple will result in an artsize of 600x600, for example! | Introduced in version 1.11 and above. |
| --minduration=x | A filter that specifies a minimum number of minutes that an album (i.e., folder of FLACs) must play for cumulatively before it can be randomly selected to be played. The default is 0, which is the same thing as saying 'by default, there's no minimum length': everything is playable (subject to all the other filters and overrides that might be affecting things) | Introduced in version 1.11 and above. |
| --maxduration=x | A filter that specifies a maximum number of minutes that an album (i.e., folder of FLACs) must play for cumulatively before it can be randomly selected to be played. The default is 525960, which is the number of minutes in a year -so, effectively means 'there's no practical upper limit on the length music can be before it is playable'.
Note that you can specify minduration on its own, or maxduration on its own, or both together. When both are specified, max must be larger than min! For example, --minduration=10 --maxduration=60 means 'play me anything that lasts between 10 and 60 minutes'. If you had said --minduration=60 --maxduration=10 (i.e., almost the same thing, but now maxduration is the smaller number), then the two parameters are silently ignored and you effectively get to play anything that lasts more than 0 minutes and less than a year! |
Introduced in version 1.11 and above. |
| --checkver | Forces the software to consult this website to see if a later version of the software is available for download. If a newer version is found, you are asked if you want to go ahead with the upgrade. If so, the newer script is downloaded, made executable and then copied to the /usr/bin folder (which will require root privileges, which are prompted for). | Introduced in version 1.14 and above. If --checkver is specified, all other run-time parameters/switches are ignored. Once the version check (and upgrade, if agreed to) has completed, the script exits. Re-run AMP from scratch without the --checkver parameter to resume normal playback functionality. |
| --colour-light | Alters the colour scheme the program displays in, to one where most text is white. Can also be specified using American spelling of 'color'. | Introduced in version 1.17. If no colour scheme is mentioned, the default is to display in a mixture of green, yellow, red and blue text, where different colours are used to convey meaning (e..g., red=errors). |
| --colour-dark | Alters the colour scheme the program displays in, to one where most text is black. Can also be specified using American spelling of 'color'. | Introduced in version 1.17. If no colour scheme is mentioned, the default is to display in a mixture of green, yellow, red and blue text, where different colours are used to convey meaning (e..g., red=errors). |
| --colour-neutral | Alters the colour scheme the program displays in, to one where most text is yellow. Can also be specified using American spelling of 'color'. | Introduced in version 1.17. If no colour scheme is mentioned, the default is to display in a mixture of green, yellow, red and blue text, where different colours are used to convey meaning (e..g., red=errors). |
| --reportdays=x | Queries the 'plays' table (when used in conjunction with --report and --dbname) and restricts the records returned to only those whose date of playing something took place with X days from "now". Thus, amp --report --dbname=main --reportdays=5 would list only those plays of music completed within the past 5 days. X must be an integer. If an invalid value is supplied, it silently defaults to being 36500, which is the number of days in a century and thus logically means the same thing as 'report everything, with no practical limits on dates at all' (which is the behaviour you get, in fact, if you don't specify --reportdays at all). | Introduced in version 1.17. |
| --reportsort=x | Specifies which column in a report of 'plays' should be used to order the output by. X is a value from 1 to 5 (because there are only 5 columns of data displayed in the built-in report), and 1 is the default anyway. So a --reportsort=2 would sort the report by its second column, which is Composer/Artist, whereas --reportsort=4 would sort the report by Genre, since that's the 4th column of the built-in report. | Introduced in version 1.17. |
| --reportexport=x | Allows the contents of the Plays table to be exported to an external text file (which may then be imported into Excel or otherwise processed by external tools). The parameter's 'x' value is the path and filename you want the text file written to. If the path doesn't exist, it will be created for you (if possible). Thus, --reportexport=/home/hjr/Desktop/myplays.txt would be valid. Spaces in the path or filename should be enclosed in double quotation marks (so, --reportexport=/home/Howard Rogers/Desktop/myplays.txt would produce an error, but --reportexport="/home/Howard Rogers/Desktop/myplays.txt" would not. The contents of the exported text file will be pipe-delimited, not comma-separated: each column is separated from the next by the | character. The --reportexport parameter can only be specified together with the --report parameter (and the --dbname one if the database to be used as the source of data is not called 'music'). | Introduced in version 1.18 |
| --setwalmode | The database that AMP uses can sometimes lock up unexpectedly, so that plays are not always recorded correctly. If the database is converted to run in 'Write Ahead Logging Mode', these sorts of lock-ups should not occur and therefore the recording of 'plays' should be more reliable. You only need to convert the database to W-A-L mode once; after it's been converted, it stays that way for all time in the future. Conversion to WAL mode does not destroy any existing data. If you specify --setwalmode when the database is already in WAL mode, a message is displayed advising you of this; no changes to the database then take place. Needs to be specified along with the --dbname parameter, so the full command would be something like: amp --dbname=main --setwalmode. | Introduced in version 1.18. Note that AMP will perform a checkpoint after every play, which should ensure lock-contention-free running of the database, with no plays left unrecorded.
Removed in version 1.20: use of WAL mode in the database is now programatically automated. |
| --device=x | Used to specify that AMP should direct its output to a named ALSA playback device. You need to know what you're doing with this one: if you send the output to a nonsense or non-existent audio device, the result will be that AMP will appear to be playing music just fine... but you won't hear anything. If you don't specify a device, the default setting is 'default', which should work for most people most of the time just fine. On my home PC, however, to get unconverted hi-res FLACs to plays at their full bit-rate and depth, I need to launch AMP with a command such as amp --device=plughw:2,0. As you can see, the device value needs to be set to technically-precise values. The command aplay --list-devices can be used to get an idea of the hardware IDs you can use that exist on your system. | Introduced in version 1.19. Unless you know precisely what hardware your PC is using and the ALSA device names/numbers to use, it is recommended to not use this particular switch, in which case AMP will direct its sound output to whatever your O/S thinks is the 'default' ALSA device. |
| --unplayed | An override that tells AMP to randomly select something to play, provided that the composer of the selected piece has never previously had something played. This might help get new additions to your music library played sooner than they would by chance, for example, without having to specify a particular composer's name (with the --composer=xxxx override switch). If a composer has not been played because he or she is mentioned in the excludes.txt file, then he or she remains ineligible to be played, even though 'unplayed' has been specified. Note that it is the composer who must be unplayed to pass this override test. If you've ever once played a 2-minute piano doodle by Lambourghini, then Lambourghini doesn't count as an unplayed composer. | Introduced in version 1.20. Only relevant if playing music with AMP using a database (otherwise, there's no store of what's been played to compare against). |
| --levelup | Tells AMP to calculate the average length of plays for all previously-played composers, and then to select something new to play only by composers who have been played, in the aggregate, for less time (or equal time) than that average.
So, say you have racked up 500 minutes listening to Beethoven, 200 minutes of Mozart and 100 minutes each of Bach, Britten and Copland. That's 1000 minutes of playing by 5 different composers. The 'global average play length' is therefore 1000/5=200 minutes. Therefore, if you next run AMP with --levelup, only Mozart, Bach, Britten and Copland will be eligible for random selection for the next play (assuming none of them are in a excludes.txt file, which is always respected; or are time-barred, which is also respected). A single play of something by Mozart will send him over the 200 minute threshold (whilst only increasing the global average by a relatively small amount), so after that one play, he won't be eligible for the next selection, and we're down to selecting something by Bach, Britten or Copland. Be aware that to be eligible for 'levelling up', a composer needs to have had at least one composition played previously, since a never-played composer doesn't have a number of plays that can be compared to anything else: use--unplayed to promote composers without even one play to their name. |
Introduced in version 1.20. Only relevant if playing music with AMP using a database (otherwise, there's no store of what's been played to compare against). |
| --composition=xxx | An override that names a specific composition to play. The xxx is the name -or part of the name- of the composition you want to hear. It doesn't mandate which particular recording of the composition will be selected for play (unless there's only a single recording of course!) The composition name is wild-carded on the 'outside', so --composition=rime will match 'Peter Grimes' and 'The Rime of the Ancient Mariner' and so on. Where a composition name contains spaces, wrap it in double-quotation marks. Thus --composition="Peter Grimes" and so on. | Introduced in version 1.20. Takes precedence over any other over-ride switch and therefore cannot be used in combination with them (which makes sense: if you ask for composition 'Peter Grimes', you've already really specified the composer and the genre!) |
| --unplayedworks | Tells AMP to randomly select a composition that has previously not been played (compare with --unplayed, which merely tells AMP to find a composer who has not had anything played previously). For example, if you buy a new recording of Beethoven's 5th Symphony, --unplayed will not help get AMP to play it, because (probably!) you've had loads of other recordings of works by Beethoven played in the past. Beethoven is not, then, an unplayed composer. But that specific recording will be potentially selected by the --unplayedworks switch (because it is that specific recording of a specific composition which is, as yet, unplayed. If there are numerous unplayed recordings in your collection, you can't tell which one will be selected for play when using this switch, but something previously unplayed will be. | Introduced in version 1.21. Takes precedence over any other over-ride switch and therefore cannot be used in combination with them. Excludes and time-bars are observed (so if you played a Beethoven piano trio at 9AM, and are using the default 6-hour time bar, that new recording of Beethoven's 5th symphony cannot be played before 3PM). |
| --xlevelup | The 'basic' --levelup switch says 'compute this composer's total play time and compare to the 'global average' of playtime for all composers... and only select this composer to be played if his aggregate play-time is less than the global average'. The new --xlevelup ("Extreme Levelup") says to do the same sort of thing, but only select a composer whose aggegate play-time is less than or equal to half the global average. So it favours composers who have very little accumulated play-time. | Introduced in version 1.23. Takes precedence over any other over-ride switch and therefore cannot be used in combination with them. Excludes and time-bars are observed. |
| --xxlevelup | This is a sort of 'Ultra Level Up' flag! The "Extra Extreme Levelup" switch says to play a composer only if his accumulated play-time is less than or equal to one quarter of the global average play-time. If you think of your composers and their accumulated play times as a bar-graph, starting on the left with those with most play-time and on the right, those with very little, this switch targets those composers on the extreme right-end of the graph. | Introduced in version 1.23. Takes precedence over any other over-ride switch and therefore cannot be used in combination with them. Excludes and time-bars are observed. |
| --stats | Used in conjunction with --dbname=xxxx, this option generates a three-line report of your database, showing total counts of composers, recordings and plays. The output is something like:
Statistic Count |
Introduced in version 1.25 |
| --pause=x | Introduces a pause of x seconds between plays within a set of selections. IE, if --selections has been set to 3 and --pause=30, AMP will play the first choice of music, then wait 30 seconds, before playing the second, then wait another 30 seconds before playing the third selection. Defaults to '1', which is essentially 'no pause between plays'. There is no limit on the number of pause seconds you can specify, but only positive integers are allowed. A value for x of, for example, 42.5 will be silently converted to '1' (the default). | Introduced in version 1.28 |