 1.0 What is AMP
1.0 What is AMP

Update November 2021: AMP was superseded by Giocoso in June 2021, and is no longer supported (though it's still downloadable if you insist). Giocoso incorporates all the key AMP features and improves on them. This article is left here for historical/reference purposes only.
AMP is a command-line FLAC audio player, with a deliberately minimalist interface. It only plays audio files formatted with the FLAC codec. It was designed for the playback primarily of classical music: that means it doesn't do randomised track orders, because classical music listeners need their symphony movements played back in the order the composer intended them to play! Accordingly, AMP simply plays FLACs in a folder in sequential order of their file names1It is assumed that your file names start with a numeric indication of the track order. We wouldn't want to play Adagio - Lento - Presto - Vivaccissimo, but if things are tagged correctly, you'd find 01-Vivacissimo plays before 02-Adagio and then 03-Lento and finally 04-Presto. Track numbers are important, in other words: I assume they form part of your track naming process. For similar reasons, AMP doesn't permit music playback to be paused or resumed: classical music people tend not to take tea-breaks in the middle of a concerto! You can interrupt play only by pressing Ctrl+C, which entirely terminates the player. Re-running AMP then resumes playback from the very beginning.
AMP also, for these same sorts of reasons, lacks track selection or volume controls: it assumed you will listen to complete compositions, in the correct order of their movements, and that you'll be listening via a reasonably decent hardware amplifier which almost certainly has a volume control knob of its own! When software starts adding 'equalizers' or 'volume controls', it's messing with -or getting in the way of- the audio signal: AMP aims to put as little as possible between your music files and their translation by your loudspeakers into sound waves.
AMP is not completely featureless, however! For starters, AMP does proper 'gapless' playback (so there will be no discernible clicks or pauses between tracks, if they are meant to run straightaway one into the other). It also 'scrobbles' by default (that is, it submits the details of the tracks you've played to the Last.fm website), so that you can review your listening habits over time. Scrobbling requires additional configuration (see Section 3.x below), but once configured it is the default mode of operation (though it can be turned off and on as required).
One other feature that AMP has which other plays tend to lack: it can be asked to select a folder of music at random from your entire music library. It will then play the contents of that folder sequentially, so it plays back in the 'correct' order. By getting AMP to select random compositions to play, however, you can avoid playing the same popular bits of classical music over and over again! AMP can therefore help broaden your classical music listening experience.
2.0 Installing AMP
Installing AMP is a simple process of issuing the following commands:
wget https://absolutelybaching.com/abc_installer bash abc_installer --amp
The first command downloads a generic installer script. The second command is an instruction to run that installer script, specifying (with a double-hyphen parameter) that it's AMP you want to install. You will be prompted at one point for your sudo password, without which the installer cannot install the software in the /usr/bin folder correctly.
3.0 AMP Running Modes
There are two ways of running AMP: locally or remotely.
In Local Mode, you physically 'cd' (change directory) to a folder containing music (FLAC) files inside a terminal session. You type the command amp and the program then plays that folder's music from start to finish, in file name order. It plays only once and then quits. To play anything else, you'd have to cd to that new folder of music and re-launch AMP from scratch. A good way to use this Local Mode is to physically browse your music collection with your distro's file manager (such as Dolphin in KDE, or Nautilus in Gnome), right-click in a folder containing the music you fancy listening to and then selecting the 'open terminal here' option:
As soon as the terminal opens, type the command amp and that folder of music will begin to play, from start to finish, in order. AMP nicely complements a good physical storage model for a music collection, in other words.
In Remote Mode, you run amp by typing a command such as amp --musicdir=/path/to/a/folder. You are pointing AMP to a folder 'somewhere over there', rather than having to go to that folder directly. So far, not so exciting: if the folder you point to contains FLAC files, AMP plays those files from beginning to end in sequence and stops, just as in local mode. But, if the folder you point to is the root folder of a large collection of sub-folders which themselves contain FLAC files, then AMP will randomly select one of those folders to be played.
So, say you have a folder structure such as:
- /Music/Antonio Vivaldi/The Four Seasons (Klemperer)
- /Music/Benjamin Britten/Billy Budd (Nagano)
If you run AMP with the command amp --musicdir=/Music/Benjamin Britten/Billy Budd (Nagano) then AMP will play the Billy Budd opera from beginning to end and then stop.
On the other hand, if you run AMP with the command amp --musicdir=/Music, then AMP will randomly select either the Vivaldi or the Britten work to play completely.
Remote Mode implies randomness of playback, therefore; but it won't be random, if you directly specify a folder which itself contains FLACs. If you specify a folder which is parent to many others than themselves contain FLACs, then it will be.
Always bear in mind, however, that that this 'randomness', if it's triggered at all, is never in terms of the order things are played back, but in terms of what gets played at all. Having randomly selected to play Billy Budd, for example, AMP will begin at the Prologue, progress through Acts 1 to 4, and end with the (spoiler alert!) hanging. Everything will be played back in track number (i.e., file name) order, in other words. The decision to play Billy Budd in the first place was randomised, but music folders are always played back entirely sequentially once they've been selected for playing at all.
A good way to use AMP in this 'random, remote' manner is to run it in a drop-down terminal, such as Guake or Yakuake:
You don't have to cd anywhere containing music; you just point AMP at the root of your music collection folder structure and let it pick what it wants to play -and then you just tuck the drop-down console away, so that it gets out of your way and continues playing in the background.
Summing up, therefore:
- If you want to be in control of what AMP plays, open a terminal, cd somewhere containing music, and type amp. (Local Mode)
- If you want to be in control of what AMP plays but can't be bothered cd'ing around a file system, type amp --musicdir=<specific folder containing FLAC files>. (Remote Mode, but no randomness)
- And, if you want to be surprised by what AMP decides to play, open a terminal, type amp --musicdir=<somewhere at the root of a set of folders containing FLACs> and see what happens! (Remote Mode, with randomness)
3.1 Running AMP for the First Time
Whichever running mode you decide to use (and you can mix and match as the mood takes you), when you first run AMP, there will be some hurdles to overcome. Depending on your choice of Linux distro and what you've already installed on it, you may find that AMP on first being run prompts you to install extra software, like this:
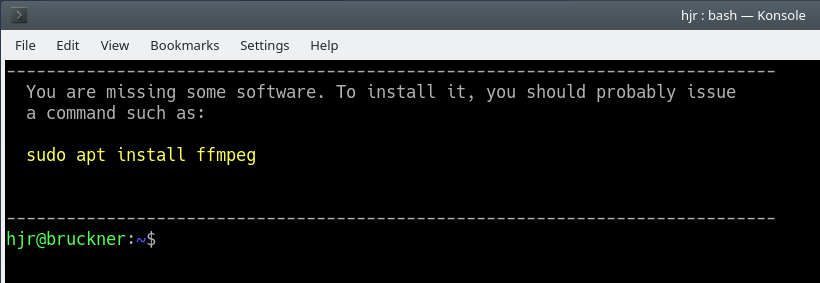
The specific software packages AMP needs to be in-place before it can work are:
- flac
- ffmpeg
- tput
- fd or fd-find (the name depends on your distro: AMP will tell you which applies to yours, if needed)
- bc
- sqlite3
Of those, only ffmpeg is likely not to be installed by default on some distros (for patent and associated legal reasons), but it's generally available in the repositories of most distros -though on Fedora, you may need to enable the RPM Fusion repository, which can be achieved by these two commands:
sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
sudo dnf install https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
Similarly, on OpenSuse, you'll probably need to enable the Packman repository:
sudo zypper ar -cfp 90 http://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_15.2/ packman
...though read your specific distro documentation to make sure, since software version numbers change over time (that last command is specific to OpenSuse 15.2, for example).
In any event, if you get prompted to install additional software, please follow the instructions provided by AMP and then re-run AMP when you're done.
Even now, however, it is likely that things won't look particularly promising! Chances are that once all the software prerequisite checks are passed, you'll be confronted by this wall of alarming-looking text:
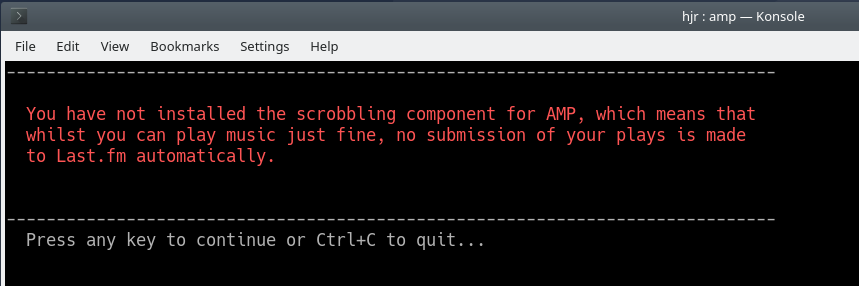
As we'll see in Section 4 below, AMP can 'scrobble' your music listening records: that just means it can 'transmit' them to the Last.fm website, so you can see your listening habits developing over time. It's a good feature (I think), but it's not essential to playing music in the first place. So, AMP will warn you that scrobbling needs extra configuration before it will work, but in the meantime, you can play music perfectly well: just press a key to continue. As I say, read Section 4 to see how to configure scrobbling -and, once you have done so, you'll find this annoying warning message disappears. Also see Section 3.2 below if you want a quick-and-dirty way to suppress the warning, by telling AMP not to bother trying to scrobble in the first place, as you invoke it.
So, let's assume you've installed all necessary software prerequisites, you know to dismiss the 'can't scrobble' warning, and you've changed directory (cd) to a folder full of FLAC files. Here's how you run AMP in Local Mode:

As you can see, I've located myself in a folder full of Symphonic files and I've simply typed the command amp. Once I dismiss the 'no scrobbling' warning, I see this:
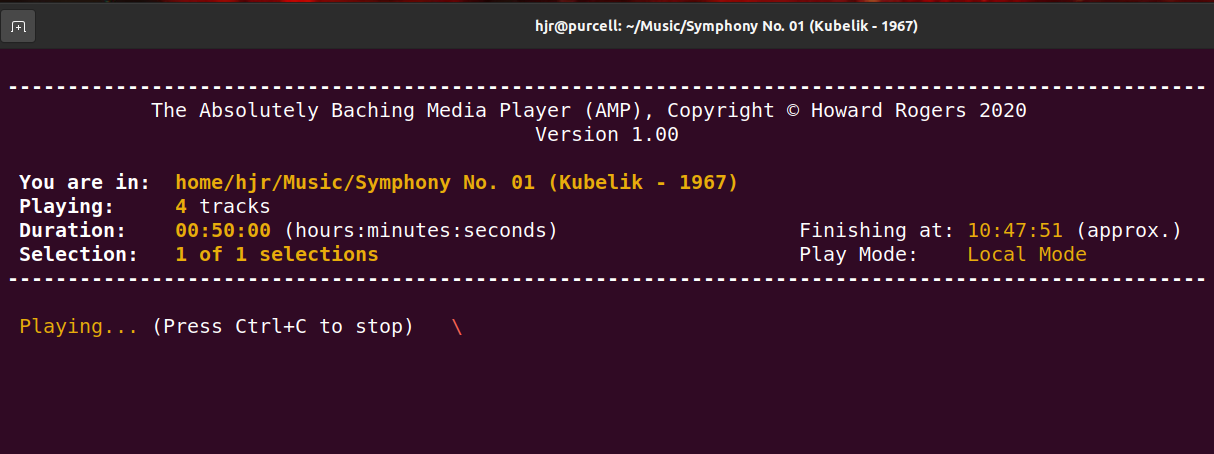
That's AMP playing the music, immediately. It tells you what folder you're in; it tells you how many music files have been found within that folder, how long they will take to play and (roughly) at what clock-time this composition will stop playing. It also provides a reminder to you whether you ran AMP in Local or Remote mode. After it's worked that lot out, it just starts playing the music. And that's it, really: it doesn't get much more complicated than that!
Sometimes, the 'You are in' folder name might be too long for AMP to display completely. In this screenshot, for example:
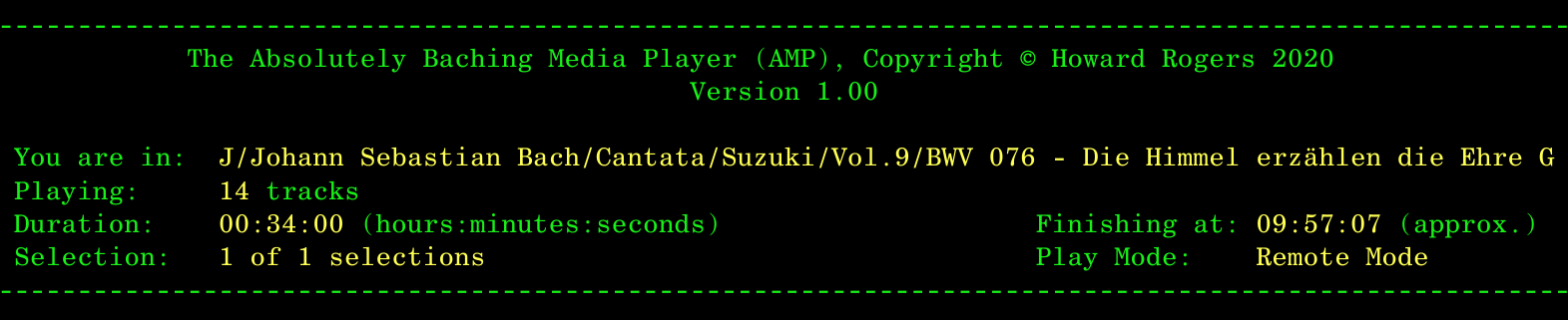
...you'll see that the very long path/filename of the Bach cantata being played has had to be truncated (at around the 85th character, if you're counting!). AMP can play in terminals that are set to the (usual) default 80 characters wide, but it much prefers to run in terminals that are set to be at least 132 characters wide!
Note that if you want to interrupt playback, you can do so by pressing Ctrl+C (that is, hold down the Ctrl and 'C' keys together, simultaneously). That will terminate the AMP program outright and music playback will stop (though it might take a second or two before the music literally stops playing, because of memory buffering).
So, in summary:
- Start a new terminal window session
- Change to a directory full of FLAC files
- Type amp to launch the player
- Dismiss any warnings about not being able to scrobbling
- Playback starts and won't stop until all the FLACs in the folder have been played in turn
- Terminate playback early by pressing Ctrl+C
If you instead wanted to play music in Remote Mode, you'd do so like this:
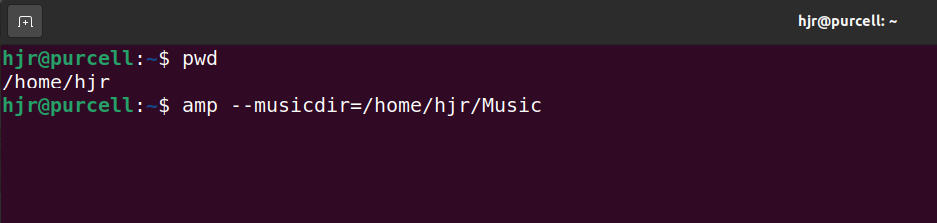
So here I am sitting in my $HOME directory, where no music is stored locally, but I'm pointing AMP at my music folder (note: always specify absolute paths to your music folders in this mode of operation. Don't start trying to use relative paths).
Pressing [Enter] at this point will still bring up the warning about scrobbling not having been configured, but pressing a key to dismiss that notice, playback will happen exactly as in Local Mode. The only exception is that what gets played will now be whatever AMP randomly selects.
And that's AMP at its simplest and most basic. Time now to investigate some of the options that can be employed when running AMP!
3.2 Suppressing the Scrobbling Warning
The 'you haven't configured scrobbling yet' warning can swiftly become annoying! Obviously, one of the ways to stop it appearing is to actually go and configure scrobbling (for which, see Section 4 below). But a quick-and-dirty fix is to append a --noscrobble switch to whatever command you use to invoke AMP in the first place. If you declare to AMP that you don't want to scrobble, then it naturally won't complain about scrobbling not being configured, even if it hasn't been!
So either of these commands would run AMP in Local or Remote Modes with no scrobble warning to start with:
amp --noscrobble
amp --musicdir=/home/hjr/Music --noscrobble
3.3 Multiple Plays
No matter which mode you run AMP in, it's capable of being told to repeat its music plays a given number of times by adding a --selections=x switch to the command that invokes it, where x is a number. When it sees that selections have been specified, AMP will perform the specified number of complete music plays before stopping.
So, let's say I invoke AMP like this:
amp --musicdir=/home/hjr/Music/Antonio Vivaldi/The Four Seasons --selections=3
Now, that's AMP being run in Remote Mode (because "musicdir" is mentioned), but it's a specific folder, itself containing music files, so there's only one folder of music to play. AMP will therefore not be able to randomly select music: you've told it precisely what to play, after all! But it will now play the Four Seasons three times in succession. Each play will be of the complete 4 movements of the work, in order, from Spring to Winter. But there will be 12 seasons in all!
On the other hand, say I ran AMP like this:
amp --musicdir=/home/hjr/Music --selections=3
Here, I'm still running AMP in Remote Mode -but I haven't specified a folder that itself contains music. I've instead pointed it at a 'parent' folder, that contains sub-folders, which contain sub-sub-folders... and they contain music files. This triggers AMP to switch into 'random selection' mode. You don't know what music AMP will now play: but it will randomly pick something. It will then play that 'something' from beginning to end. It will then randomly pick something else, and play that completely. And finally, it will pick a third folder of music and play that completely. In this configuration, 'selections=3' doesn't mean 'play something three times over and over', but 'pick three different things, and play each one completely before moving on to the next'.
Finally, you could invoke AMP like this:
cd Music/Antonio Vivaldi/The Four Seasons amp --selections=3
That's AMP being invoked in Local Mode (because I've cd'd to the folder containing a specific set of music files), but the selections switch is still valid. This will play all four movements of the Four Seasons concerto over and over, three times in succession.
Whenever you've specified the selections switch, the AMP display will tell you where it's up to within its cycle of plays:
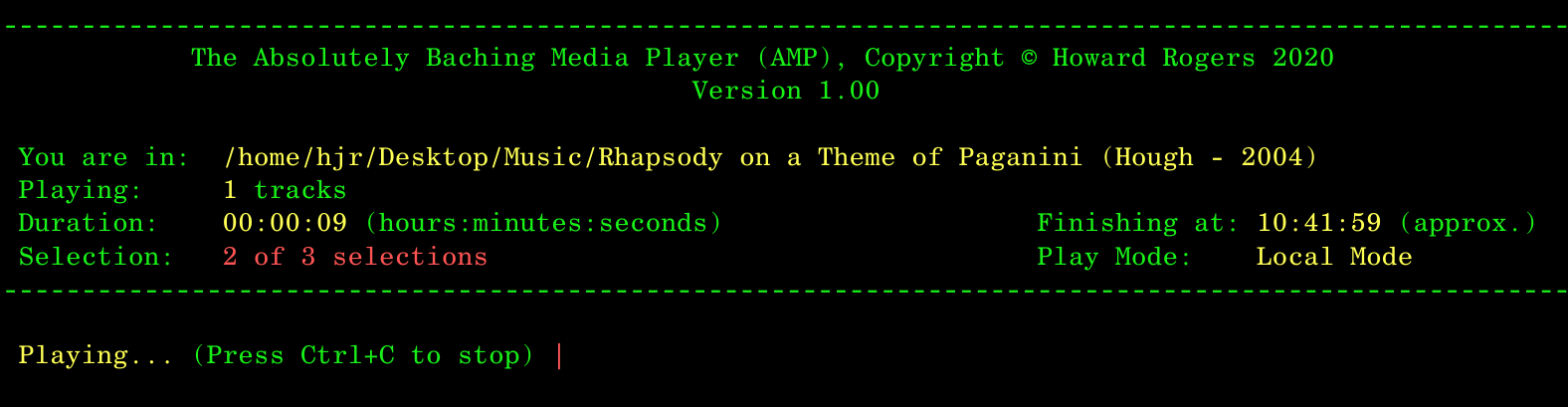
Here, I know I've specified selections=3 and that I'm currently listening to the second of my listening cycles. Since the display mentions I'm in 'Local Mode', I know that I'm in a specific folder of music files -so AMP must be playing the same folder over and over three times.
Incidentally, there's no limit to what you can specify for the selections parameter. This is perfectly valid, in other words:
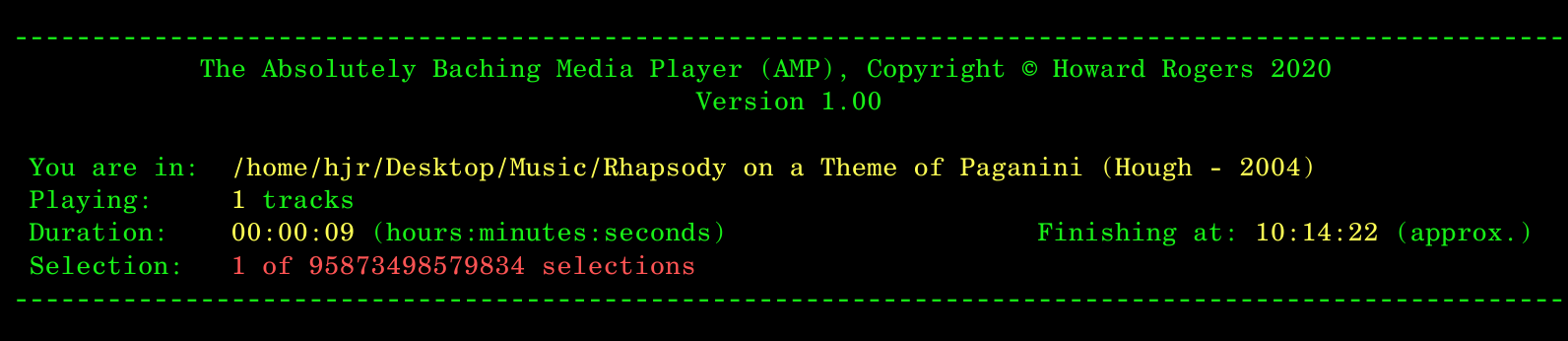
Though you probably need to check in to a 'facility' somewhere if you really want to play the Rhapsody on a Theme of Paganini that many times! If you try to set it to a non-numeric value, however, the program will assume you meant to type '1'. So --selections=MMXXI will be treated as 'selections=1': no Romans allowed!!
Finally: just note that the 'Finishing at' display at the top of the command window is only the time that the currently playing selection is due to finish. AMP cannot tell you when your 3 or 4 or whatever selections will end, because of course, it may be making those further selections at random in the future. It doesn't yet know whether it's going to be randomly choosing a Wagner opera or a Vivaldi violin concerto, so it cannot possibly tell you when the entire cycle of plays will end.
3.4 Excluding some composer from random selection
It is possible that whilst you're happy to have AMP pick music at random, you'd rather it didn't pick the music of specific composers. In my case, for example, I would not want AMP to randomly select the works of composers like Britten, Bach, Vaughan Williams and so on: those composers are already in my 'top 10 list' of composers I listen to a lot, so having AMP re-inforce their hit status by randomly selecting them for play rather defeats the purpose of random selection: I want AMP to play composers I rarely listen to, not ones I always listen to!
If that's a consideration, then create a text file in $HOME/.local/share/amp called excludes.txt. Here's mine:

With one name per line, and making sure not to have blank lines at the end of the file (which is why 'Wolfgang Amadeus Mozart' bumps straight into my command prompt at the end in that screenshot), you've just allowed AMP to make sure not to randomly play music from any folder that contain these exact names. So make sure you type the names into the excludes.txt file precisely as they are used throughout your music collection. If you spell Handel with an ä when tagging your music, for example, then make sure you spell it with an ä in the excludes.txt (and stop doing that: it's not the correct way of spelling his name at all!)
Try not to have too many composers listed in your excludes.txt: the longer your list grows, the longer it will take the random selection process to find a composer's work who shouldn't be excluded. I would suggest listing a maximum of around 10 composers to make the wait for random selections bearable.
If no excludes.txt exists in the $HOME/.local/share/amp location then all music files are valid random selections -and you'll get to listen to anyone's music that AMP happens to pick on.
4.0 Scrobbling
Scrobbling is the act of uploading details about the music you've played to the Last.fm website, where you can later review your accumulated listening habits. I find it useful, to make sure I'm not over-playing one composer, or underplaying another.
AMP can scrobble your music listening statistics and will do so if it can by default... but it isn't configured to do so out of the box.
4.1 Configure for Scrobbling
To get scrobbling to work, you must first create an account at Last.fm (which is free to do, but is completely independent of anything to do with this website, so don't complain to me about them, please!)
Once you have logged in to your new Last.fm account, you need to do something they call 'creating an API account' -which sounds much worse than it is! Just visit this link and you'll see this screen:
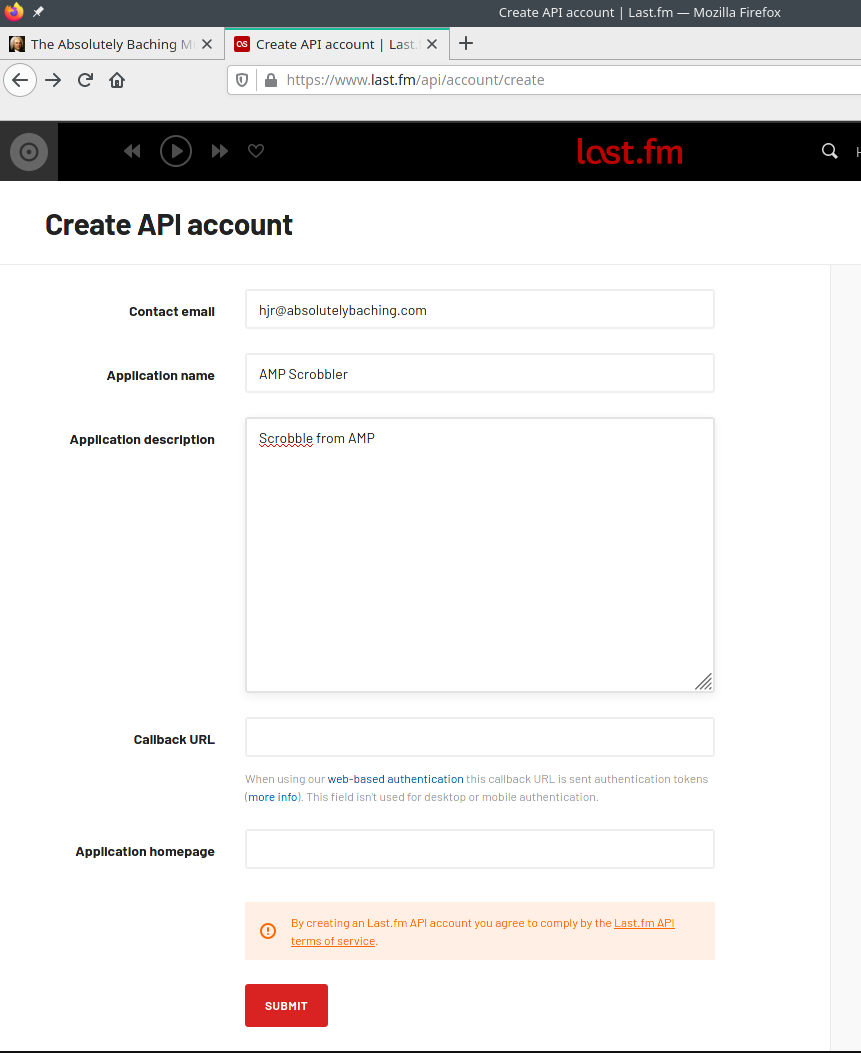
Fill the screen in as you see here: obviously, your email address will be different, but otherwise just type in equivalent entries. In particular, don't feel you need to enter a 'Callback URL' or an 'Application homepage': just leave those blank. Click [Submit] when you're ready and the screen will change to display this sort of thing:
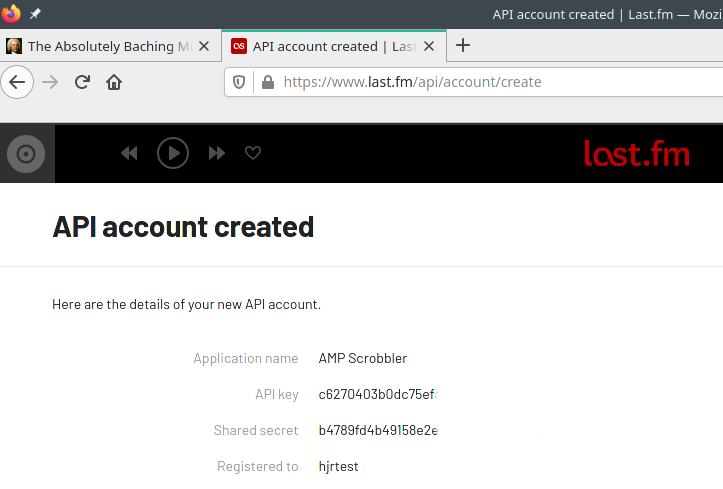
Take a note of the 'API key' and 'Shared secret' numbers displayed here: you're going to need them in a moment. It's probably best to copy-and-paste them into a text editor so that you don't make any mistakes when using them shortly.
So that's all you need to do on the Last.fm side of things: create an account (which you'll need to verify by clicking a link they send you via email) and then creating an API account (and making a copy of the API key and Shared secret they tell you about when you do so).
 You then need to download an additional Bash script, which you can do by clicking this link.
You then need to download an additional Bash script, which you can do by clicking this link.
Assuming that you have downloaded that script to your $HOME/Downloads folder, you need to then install the script by running the following commands:
sudo chmod +x $HOME/Downloads/amp-scrobbler.sh sudo mv $HOME/Downloads/amp-scrobbler.sh /usr/bin sudo ln -s /usr/bin/amp-scrobbler.sh /usr/bin/amp-scrobbler
Taken together, those commands make the new shell script executable, move it to a directory that is usually in your PATH (so the program can be found when invoked) and creates a shortcut to it that lacks the '.sh' extension, so the program can be invoked by a plain 'amp-scrobbler' command instead of having to type 'amp-scrobbler.sh'. All the commands are essential: don't miss any out.
So, with your Last.fm account set up and capable of being logged into, and the amp-scrobbler program downloaded and installed, you now need to perform the amp-scrobbler initial configuration.
Open a command prompt and type:
amp-scrobbler --connect --api_key="c6270403b..." --api_sec="b4789fd..."
I've only typed in the start of each of my API keys and shared secrets: you obviously type in both pieces of information in their entirety (and this is where copying-and-pasting comes in handy, because you need to get both of them spot-on).
If at this point, you see this sort of message:
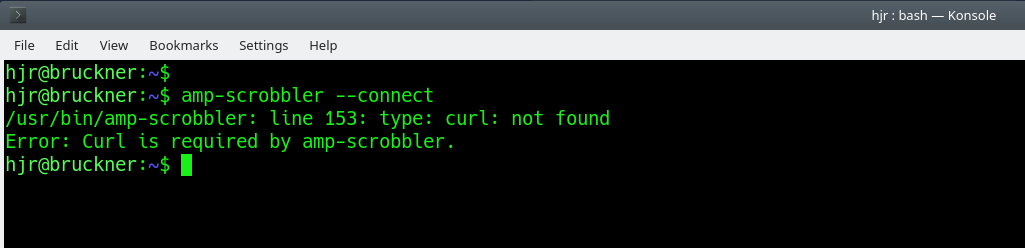
...then you must first use your distro's package manager to install the curl program. So on Debian, that would be a sudo apt install curl; on Fedora, a sudo dnf install curl and so on. Once curl is installed, you can re-run the amp-scrobbler --connect --api_key=... command. This time, you should see this:

This is just an informational message to get you started. Press the [Enter] key to get things actually underway...
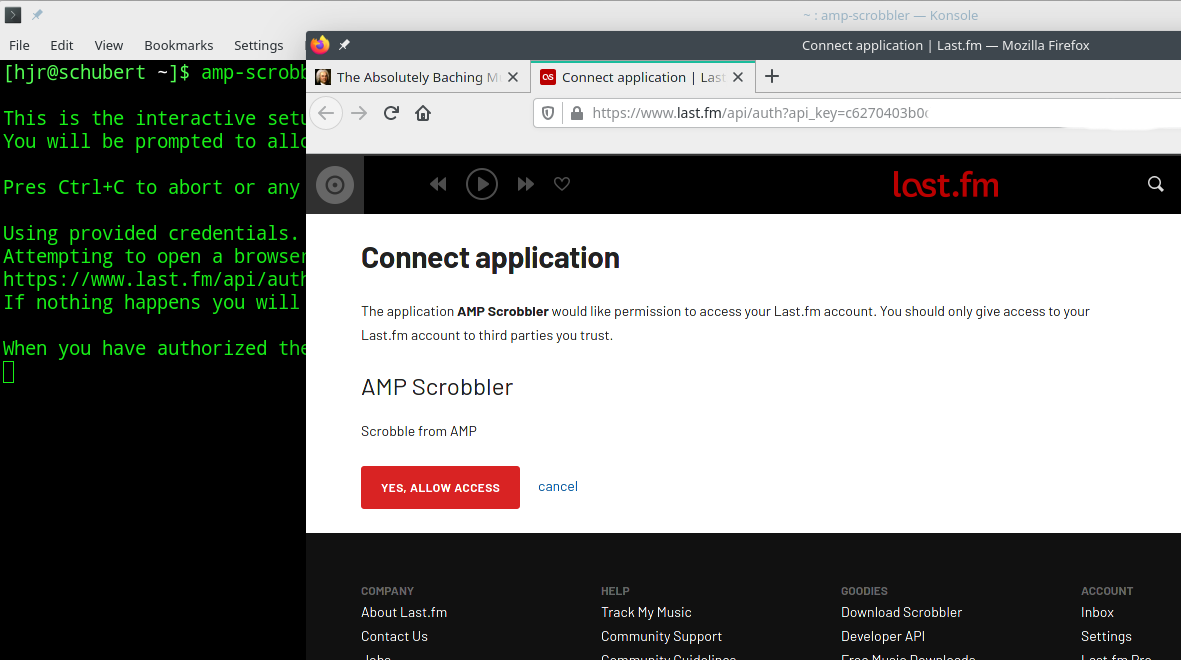
What's happening at this point is that the amp-scrobbler has generated a URL (web page address) using your new API Key. It's then opened a web browser at this new address -and the page asks you to authorise the AMP Scrobbler to be able to post details of what music you play to your Last.fm account. The correct response here, then, is to click the [Yes Allow Access] button... and then you're done.
Sometimes that web browser opening bit doesn't work automatically. As the amp-scrobbler screen tells you, though, if that happens, you simply need to copy the URL the program has generated out of the terminal session and paste it into a browser you've manually opened yourself.
You may also have to manually log in to your Last.fm account before you see the 'Connect application' screen shown above.
But if you make it to clicking the 'Yes Allow Access' button, and receive a green confirmation message that 'You have granted permission to AMP Scrobbler to use your Last.fm account', you are all set to scrobble with AMP. And you'll be pleased to know that you only ever have to do this once!
To finish things off, you now just close the web browser and return to the command prompt. Press [Enter[ to tell the scrobbler that it has been authorised: and now you're ready to scrobble.
4.2 How AMP Scrobbles
Unlike most other media players out there, which scrobble each track as you play it, AMP takes the more 'classical music' approach of not scrobbling something until you've played all of it! So if you're playing the four movements of a symphony, then nothing of those tracks is scrobbled to Last.fm until the end of the fourth movement. When it does so, you'll see output like this:
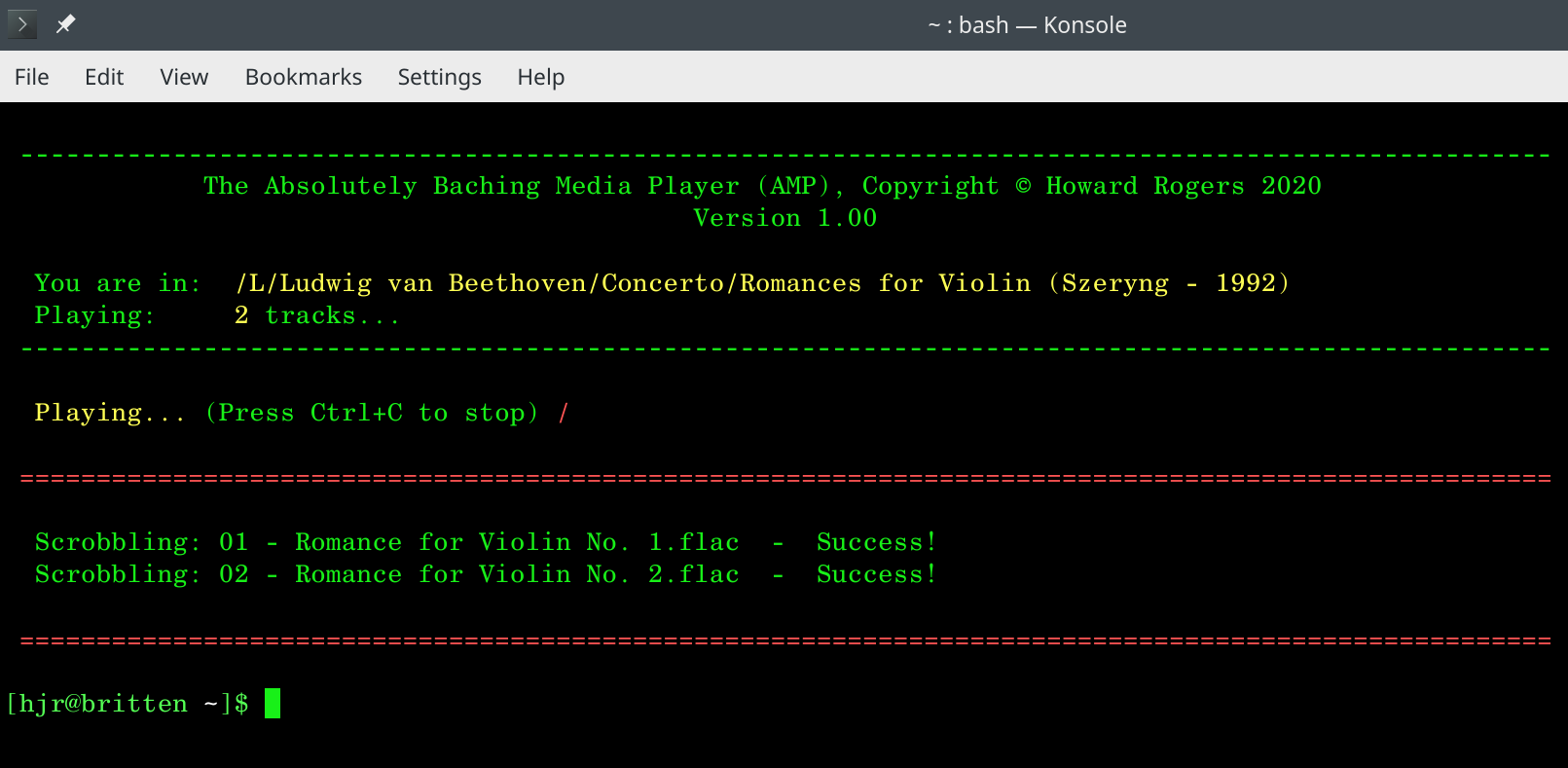
Here you see I've been playing the two tracks in a folder of Beethoven violin romances. When the second one finished, two messages about 'Scrobbling:...' are received as both are scrobbled at the same time. Note the 'Success' message at the end of each scrobbling message, letting you know that Last.fm has received the scrobbles correctly. (If you see lots of failure messages, check your PC's clock time and perhaps synchronise it with an NTP time source, as Last.fm gets a bit cranky if it sees you attempting to scrobble songs claimed to have been played several minutes in the future!)
Be warned that this 'delayed' scrobbling mechanism (i.e., scrobble nothing until everything in a folder has been played, then scrobble the lot) means that if you interrupt playback half-way through a folder containing, say, 68 tracks... then there won't be a record of the 34 tracks you did play at Last.fm. Interrupt playback (with Ctrl+C) and you abort the program before it even attempts to scrobble.
In my mind, that's the correct thing to do! Again, classical music is different from non-classical music. If a symphony consists of 4 movements and you leave the concert hall after the second movement, then you haven't listened to that symphony... and, in the same way, Last.fm shouldn't record you having listened to 'some' Beethoven if you haven't stuck it out until the end!
You might not agree with that thinking... but it's the way I think about my music listening, and I wrote the software... so you're kind of stuck doing it my way if you want to use AMP!
Finally, if you specify the --selections=x switch when running AMP, scrobbling will take place after each 'play cycle'. If you'd said --selections=3, for example, then AMP will play something and scrobble it; play something else and scrobble that; and then play the third selection and scrobble that. Interrupt AMP in the middle of a long cycle of multiple selections, therefore, and some of the music you've played will still have been scrobbled, provided you've at least run through one complete 'play cycle'.
4.3 Scrobbling and Embedded Cuesheets
With the writing of CAO ("Composition-at-Once"), I made scrobbling life rather harder for myself! The idea of CAO is that you turn a folder full of little FLACs (one-per-track) into a single super-FLAC (one-per-composition). The single track then gets played as a single 'thing', just as AMP plays a folder full of little FLACs, so there's no great change in playback behaviour. But if there is only one super-FLAC actually, physically present then AMP would previously have only scrobbled the playing of one track of music. But, inside the super-FLAC created by CAO, there's actually an 'embedded cuesheet', which tells music players how to 'interpret' the single, large FLAC and 'see' within it all the individual tracks that originally existed and got combined into the super-FLAC. It seems appropriate to me that, though only a single super-FLAC of Beethoven's Symphony No. 9 exists on disk, we should nevertheless record that you listened to the four movements of that symphony; and that means scrobbling four things, not one.
So, the short version of this is that provided you are using AMP Version 1.04 or above, AMP will detect the presence or absence of an embedded cuesheet in the FLAC file it's playing. If it finds an embedded cuesheet, it scrobbles individual tracks from there. If it doesn't, it scrobbles as it always did, by physically stepping through all the FLACs found in a folder and finding out who their composer was, what that file's TITLE tag is set to and so on.
The even shorter version is, whether you use CAO to create super-FLACs or not, AMP will correctly scrobble on a per-track basis.
4.4 Runtime Disabling of Scrobbling
Even though you may generally want to scrobble -and go through the sign-up at Last.fm and amp-scrobbler --connect process to make it happen- there will perhaps be times when you wish scrobbling didn't take place.
For example, when I download new music from the likes of Prestoclassical, I can pretty much guarantee that they will be tagged incorrectly, attributing a Beethoven symphony to Leonard Bernstein or The Royal Liverpool Philharmonic Orchestra, for example. I really don't want to see those sorts of 'artist names' appearing on my Last.fm statistics (where, for me, Artist=Composer, not the performers on a particular recording). So, whilst I might be keen to play my new purchase, I'm not so keen on its (wrong!) tag data being uploaded to Last.fm.
AMP can help you here, because it can be run with a --noscrobble runtime parameter. If AMP spots that at the time it's being invoked, then even though all the scrobbling technology has been installed and configured, it won't scrobble. For example:
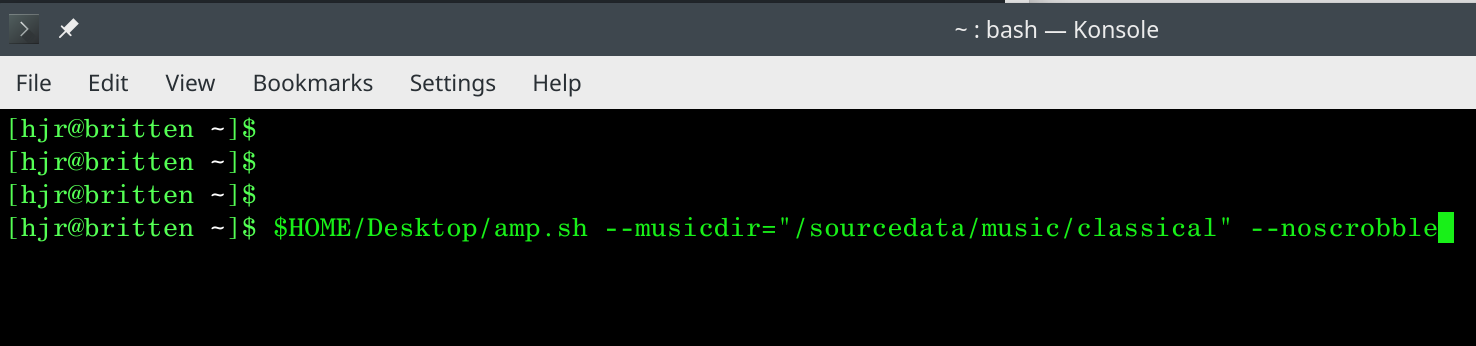
That's me asking to do a random play of something in my music library ...but not to scrobble it once playback has finished. Once the last of the tracks of my randomly-selected composition has finished playing, I'll see this:
...which simply indicates that playback has stopped, and no scrobbling was attempted, because it had been manually turned off.
4.5 Manual Scrobbling
Sometimes, the amp-scrobbler will not return 'Success!' messages when scrobbling, but will (for assorted reasons -including the Last.fm servers being down for maintenance!) report errors. If that happens, you can either just shrug and move on, accepting that those 'plays' are now lost from your Last.fm statistics... or you can use the AMP fall-back scrobbling capability to correct the situation!
Whenever AMP plays anything, assuming you haven't disabled scrobbling, as well as transmitting the play information directly to Last.fm, it also writes the plays out to a text file: $HOME/.local/share/amp/scrobble.txt. That file is always re-initiated every time you start to play something new, but before that point, it will contain the records of what you last listened to.

As you can see, the data is stored in a series of comma-separated values. The various fields within the file are artist, track, album, timestamp (i.e., the precise time the track was played, where 0 is January 1st 1970 and the number displayed is the number of seconds which have elapsed since then), and finally the duration of the track, in seconds.
By itself, having this information available in a text file is not terribly useful... but if you visit The Universal Scrobbler, it might be!
At the Universal Scrobbler, you can log in (to your Last.fm account: there's no separate 'universal scrobbler' account required). You can then 'scrobble manually', where you type in the five pieces of information that are stored in the AMP text file, by hand. Or you can 'scrobble manually in bulk'... where you can literally just copy-and-paste the contents of the ~/.local/share/amp/scrobble.txt file into the web page and have it bulk-uploaded to Last.fm that way. Any scrobbles that AMP itself failed to achieve successfully can, therefore, be 'back-filled' by making use of the The Universal Scrobbler and the ~/.local/share/amp/scrobble.txt that AMP itself produces.
One note of caution: you can only use the 'scrobble manually in bulk' if you pay for the privilege -but the payment options seem extremely reasonable to me. I think US$5 for a life-time ability to scrobble in bulk via CSV is a bit of a bargain -though, I would note, that the website hasn't been updated since 2016 or so. That might just be because the site does what it says it will do on the tin and there's no need to update it. Or it could mean the developer has lost interest in it, which might mean that your 'lifetime payment' suddenly has a much shorter life-span than you were expecting! Caveat emptor, basically.
Also, one word of warning: the text file is produced by AMP as well as auto-scrobbling to Last.fm. If you submit scrobbles via ~/.local/share/amp/scrobble.txt+Universal Scrobbler, you could potentially be duplicating scrobbles, which isn't 'the done thing' at all. Only use the text file to 'repair' your scrobbles when AMP itself fails to scrobble correctly and gives you a clear error message that auto-scrobbling for a track has failed.
Additionally, note that the auto-scrobbling mechanism produces its own record of successful and unsuccessful scrobbles at ~.config/amp-scrobbler/scrobbles.log (that is, in a folder stored within the hidden .config folder that sits inside your $HOME folder).
Finally, note that Last.fm has its own rules about scrobbles that it will apply no matter what you do. In particular, any scrobble of a track that lasts less than 30 seconds will not appear in your listening statistics, even though AMP and amp-scrobbler believe the scrobble was submitted 'successfully'.
5.0 Using a Database
From version 1.02 onwards (released on 10th January 2021), AMP can be told to create, refresh and use a small database to assist it its decisions of what to play or not to play. Use of such a database is entirely optional -and, if you tell it to use a database when one doesn't exist, it simply falls back into the 'physically scan files' modes described above and so will continue to function perfectly well.
The main purpose of making AMP use a database is simply one of speed: if your music collection is many tens of thousands of FLAC files big, then scanning through that to pick a folder to play at random (as described in Section 3.0 above, when remote mode is invoked, but with --musicdir pointed to a folder which doesn't itself contain music files, but is the parent folder of child folders that do) can take quite a bit of time. That means AMP launches quickly enough but might then take quite a few seconds to start playing something.
If, instead, you 'concentrate' all the details of what music you have into a small database that's maybe only 20MB and only a few tens of thousands of data rows big, randomised selection of something to play is almost instantaneous.
Moreover, if randomised play selection is based on a physical 'walk' through your collection, the size of the various parts of your collection will affect the random outcome: if you have lots of Bach, lots of Beethoven and very few Frank Bridge tracks, then the chances of AMP picking any Frank Bridge to play will be very small. But in AMP's database, every composer is represented by one row -so selecting randomly from a three-row table means Bridge gets a 1-in-3 chance of being picked, equal to Bach and Beethoven. Suddenly, small, unusual corners of your music collection get just as much a chance of being selected for play-at-random as the traditional 'big name composers' -and that's good from the point of view of making your listening more diverse and from a broader repertoire.
A final reason for using a database is that it makes your collection amenable to logical searches in a way that you are seldom able to do with standard music player/manager: you can open the database in third-party tools and inspect the contents of the database directly. This can reveal metadata tagging errors that have taken place long ago, for example.
5.1 Creating a Database
If you want to use a database with AMP, then you must first create it. Do so with the command:
amp --createdb --dbname=<something> --musicdir=/somewhere/your/music/files/are/stored
The "--createdb" parameter is the one that actually triggers database creation. You don't have to name your database with the "--dbname" parameter: if you don't, it will be called music. If you do want to use a specific name, provide it after the equals sign, without spaces. If you insist on having spaces in the name, wrap the name in double quotation marks. Finally, use the "--musicdir" directive to tell AMP where it should scan folders to discover FLAC files.
All these are therefore valid ways to create an AMP database;
1) amp --createdb --musicdir=/music 2) amp --createdb --musicdir=/music --dbname=main
In (1), you'll get a database called "music" (because you haven't specified a database name), that will contain the summarised contents of a scan of the /music folder.
In (2), you'll get a database called "main" (because you did specify a database name), that will again contain the summarised contents of the music folder.
The database created takes the form of a SQLite file with the database name, and a .db extension, created in $HOME/.local/share/amp. Note the period (fullstop) at the front of the 'local' folder name: it means it's a hidden folder and you'll need to turn on hidden file/folder visibility in your file manager to find it.
As soon as the database file is created, AMP prompts you to press a key to continue and, when you do press a key, it runs off to the specified musicdir and starts a fast scan of the folders found there. Details of the FLAC files found in that folder structured are then used to populate the database, which can be used immediate thereafter.
5.2 Playing music via a Database
Even if you've created a database, AMP won't use it unless you specifically tell it to do so. To do that, you have to add another parameter to the command line when invoking AMP, as follows:
amp --musicdir=/somewhere/my/music/lives --usedb
It should be noted that, technically, a --musicdir parameter is not needed when using a database, as the database itself contains all the folder names and paths where music files resides. It's use is still recommended, however, for cosmetic reasons: if AMP knows that /somewhere/music/lives is the 'root' of your music collection, when it plays music from /somewhere/music/lives/Beethoven/Symphonies/Symphony No. 5 it will know to 'chop off' the /somewhere/music/lives folders when displaying the music that it is playing. It just looks a little tidier to remove the 'root' of your music collection from the dispayed paths. But, as I say, it's not necessary to specify a musicdir.
It is the "--usedb" parameter which tells AMP to use or not use a database, of course -but it doesn't tell AMP which database to use! Since no specific database name has been provided, AMP will fall back to assuming the use of the default database, which is called music. If there isn't a database of that name, it will warn you but continue to play music from the musicdir anyway (another reason for wanting to specify it, even when database use is requested).
To specify a non-default database, use the --dbname parameter once more. For example:
amp --musicdir=/somewhere/my/music/lives --usedb --dbname=main
...tells AMP to use the non-default dataabase called "main", assuming it exists; if it doesn't, it will again warn you and continue playing from the musicdir specified anyway.
5.3 Refreshing a Database
If you change the state of your physical music collection in any way, then AMP used without a database will be aware of that change immediately... but AMP used with a database will not know about it, because the database was created and populated before the physical changes were made. So, if you acquire 4 new CDs, or correct some bad tagging in an existing music file, or delete a CD or two as no longer being worth having... AMP in database mode won't know about any of that happening unless you tell it.
You tell it of such changes to your database by running a database refresh, using this sort of syntax:
amp --refreshdb --dbname=main --musicdir=/somewhere/music/lives
The "--refreshdb" parameter tells AMP to update its database records by performing a fresh scan of the music files stored within the specified "--musicdir". Note again the use of a "--dbname" parameter to let AMP know which database should be updated: miss that out and AMP will attempt to update the default database called music.
When you issue this sort of refreshdb command, AMP will find all the FLAC files in your music collection -but will only read the metadata from the first file it finds in each folder. If you've got a folder full of 68 tracks of a big 5-Act opera, for example, only track 1 will be read to find out the composer, the composition name, the year of recording and so on. That obviously saves reading the other 67 tracks (which, in theory, should all be tagged identically, given they're all from the same opera written by the same composer and recorded at the same recording session as track 1!), and therefore this sort of refresh (the default type) is called a fast refresh. Fast refreshes are the default mode in which AMP updates its database.
It is also possible to add a "--scanmode=full" parameter to the above command to force AMP to perform what's called a full refresh. A full refresh pulls metadata out of every single FLAC file it finds. It then summarises all that track-specific information into album-wide information, which AMP then uses to decide what to play (remember, AMP never plays individual tracks, only complete folders of music (where one folder stores one composition).
Given AMP only plays complete folders, the collection of track-specific metadata is really, functionally, pointless: a full refresh gets 'boiled down' into the same sort of data a fast refresh would have created anyway. However, it can be useful to have two different ways of acquiring the same information: the different methods used might expose problems with your metadata, for example, that would otherwise not be noticed.
For example, suppose you had labelled Track 53 of your opera as having been recorded in 1987 when the other 67 tracks all say it was recorded in 1986. The fast refresh only looks at the recording year that track 1 is tagged with, so it will declare there is one album, recorded in 1986. When AMP plays that folder, the fact the metadata is 'off' in track 53 won't make any difference to it, since it plays all FLACs in a folder, regardless.
Now say you scan that same folder with a full refresh. AMP will now spot that track 53 has a different year from the rest and will create two album records for that one folder in consequence: one opera recorded in 1986, and another one (comprised of a single file) recorded in 1987. Practically, this makes no significant difference: AMP knows that both 'albums' live in the same folder, so if it picks either of them to play at random, it will end up playing all 68 tracks of the opera regardless of which 'album' record made it visit that folder. Technically, the album just became ever-so-slightly more likely to be picked for random play, because it is now represented by two rows in the table, not one... but in a decently-sized music collection, the difference is going to be negligble.
All of which is by way of saying that whilst a full scan is of interest, and may be helpful in tracking down metadata tagging errors, it's really not of any practical significance and therefore you are advised to refresh your databases with the default fast scan method instead.
If your music collection is forever changing, you might want to schedule a "--refreshdb" every night or so (using cron). If it's fairly static, a refresh done once a month or even once a quarter might be sufficient for your purposes. Here's my crontab, anyway:

Notice how, by cunning use of the dbname parameter, you can refresh different databases at different frequencies and on different schedules.
5.4 Databases and Excludes
If you tell AMP to use a database, you need do nothing else to tell it to make use of the 'excludes' functionality that was described in Section 3.4 above. That is, if you've created a text file in $HOME/.local/share/amp called excludes.txt then AMP will make use of its contents to prevent music by any named composers from being randomly-selected for playback.
As previously described above, the excludes.txt file must consist of one composer per line, and the composer name must precisely and exactly match the way you've tagged the ARTIST tag in your FLAC files. If you've asked to exclude Mozart, W but tagged your music as being written by W. Mozart, then none of Mozart's music will be excluded, because the two names don't match exactly. Even if you type W. mozart into the excludes.txt, that still won't work, because capital M in the tag doesn't match the lower-case m mentioned in the excludes file.
Exact means exact!
But if you meet that hurdle, then database-mode AMP will respect your excludes just as it would in non-database mode.
Since AMP version 1.06, AMP has also placed a 'temporary exclude' on anything that is 'time-barred'. By default, a composer is 'time barred' from being selected for further play if he (or she!) has had some music selected for play within the last six hours. So, imagine something by Britten happens to get played at 9AM... AMP will not randomly select anything else of Britten's to be performed until 3PM that day.
This behaviour can be modified by providing a --timebar=x runtime parameter when running AMP, where 'x' is the number of hours a composer will be time-barred for. Valid values for x are any integer value between 0 and 9 (note: from version 1.26 and above, the allowed interger value is between 0 and 999 hours, which is just over a month). A setting of 0 is effectively the same as saying 'there is no time bar: all composers (if they are not in the excludes file) are valid selections'. A setting of 9 would mean Britten in the earlier example couldn't be a candidate for playing until at least 6PM. In version 1.26, a setting of 99 would essentially mean nothing more by Britten could be played until around 4 days had passed; a setting of 999 would mean no more Britten could be played for about another 40 days. (Remember, though, that you can always run AMP again with a different --timebar value, so if after 14 days, you were missing the sound of Britten, there's nothing stopping you from running AMP with a setting that would permit Britten to be played once more (if you wanted to force it, --composer=britten would do it!)
5.5 Play History
When AMP is invoked in a way that mandates the use of a valid database, any music then played by AMP will be recorded in a 'plays' table contained within that database. The table stores when playback of a recording finished, who its composer and performer were and what its genre was: AMP obviously gets that information out of the audio file's own metadata tags, of course. Note that it only fetches the data from the first FLAC file found in the playing directory, just as happens during a fast scan.
You can access the plays table using any SQLlite 3 client, such as the DB Browser for SQLite. Alternatively, you could do this at the command line:
sqlite3 "$HOME/.local/share/amp/main.db" -cmd ".mode column" -cmd ".headers on" \ "select strftime('%d-%m-%Y, %H:%M',playdate) as PLAYTIME, artist, album from plays;"
That assumes the use of a database called "main.db", but change the name to suit what your database is actually called and that SQL statement will produce a report of everything you've listened to since you started using AMP (the table is cumulative over time):
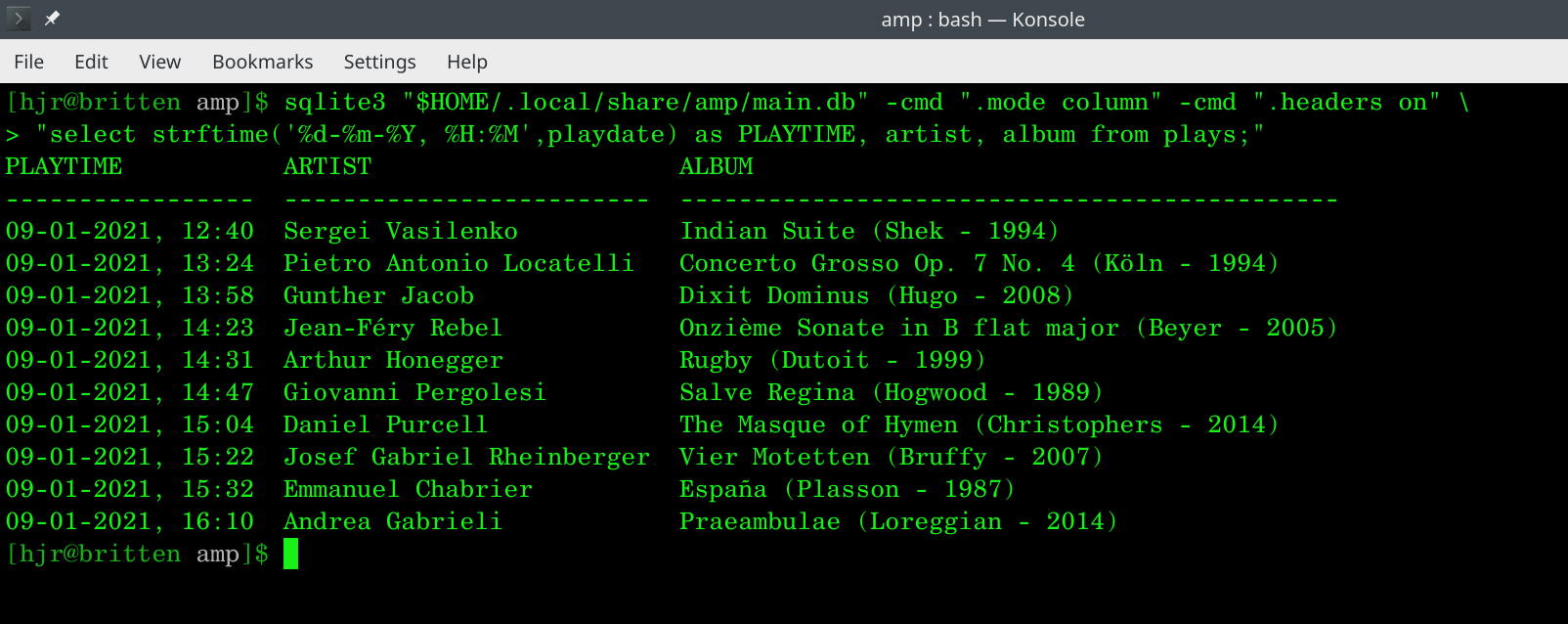
Tweaking the SQL to add a WHERE statement, so that only listens since a certain time are shown, or that some aggregate statistics are shown, is always possible -but somewhat outside of scope for a how-to on using AMP itself! The data will be there when you're ready to record it, is the main point 🙂
In AMP version 1.03 and above, a new command line switch has been created that will allow you to view the Plays table in very much the way you see above. You need to invoke AMP by specifying the database you are interested in with the --dbname parameter (as ever, if you don't do that, we'll assume a name of 'music' for the database. You then add --report to the command line. So the whole thing ends up looking something like this:
amp --report --dbname=main
(The ordering of the 'report' and 'dbname' parameters is not important, so long as both are present somewhere). That will produce this sort of output:

Notice the little colon sign at the left of the bottom-most row? That tells you that this screen-full of information isn't the end of the list. You can press the down-arrow cursor key to scroll on down to see the rest of the report -or the up-arrow key to scroll back up the report. When you're done, just press the letter 'q' (to 'quit') and you'll be back at the command line. If you want to see different columns in different orders and only the 'plays' for a particular date-range: well, that's not what this --report option is intended to do... and it's time you learnt to use some third party SQLite client tools instead!
In concluding, note that adding records to the plays table always happens when you say to run AMP with a database. The data collected is pretty similar to what would be scrobbled to Last.fm, if you enabled that -so, you can think of 'plays' as being a kind of 'internal scrobble'. But since the data collected is always retained locally and privately, within the AMP database, it's not considered a 'true scrobble' and therefore the data is collected whether you say --noscrobble or not. You can always delete the plays table via a SQLite3 client at any time if its existence causes you worry.
5.6 Database Statistics
A sort-of high-level alternative to the --report option is the --stats option, available from version 1.25 onwards (and tweaked in 1.26 to display more information is a slightly nicer format). Invoke it like so:
amp --stats --dbname=xxxxx
As usual, if you don't supply a specific database name to query, AMP will assume you mean a database called 'music' (and will error if no such database exists). No other options are needed: the command immediately outputs something like this:
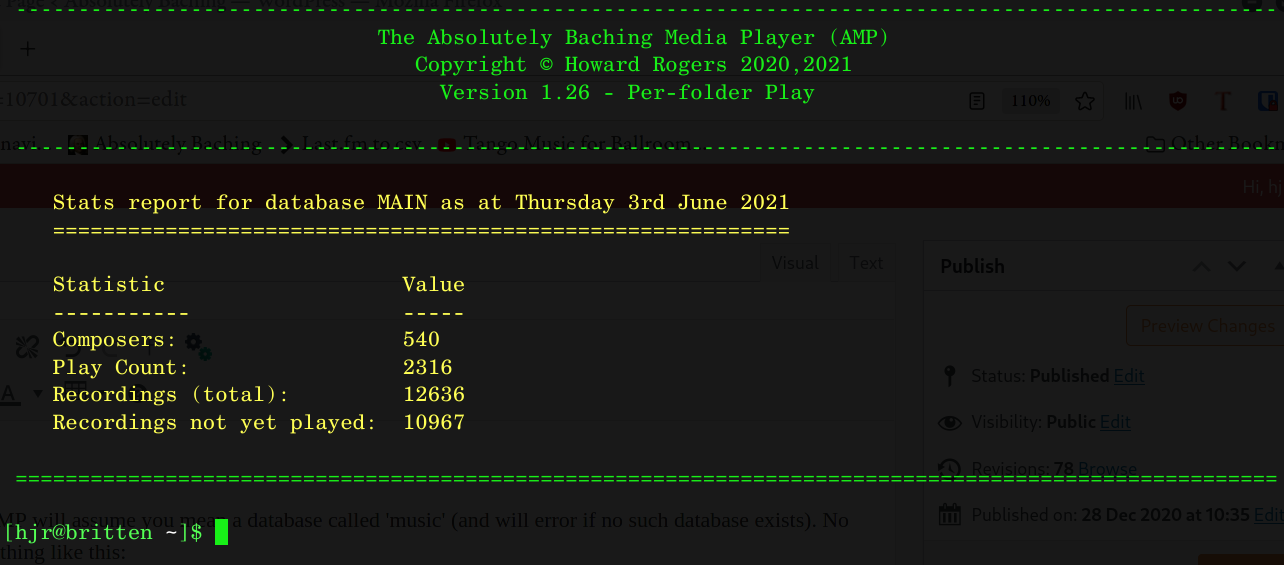
Four statistics are displayed (only 3 in version 1.25, 4 from 1.26 onwards) Composers is simply a count of the number of unique composer names (i.e. derived from the ARTIST tag) you have in the database. If you've tagged your music inconsistent as 'Wolfgang Mozart', 'Mozart, Wolfgang' and 'Wolfgang Amadeus Mozart', this statistic will display '3'. It cannot know that three completely different spellings represent the one composer!
The Play Count is simply the number of records in the PLAYS table within the database. That is incremented by 1 every time a complete composition is played from beginning to end. So if you play Beethoven Symphony No. 5 and Symphony No. 7, that statistic will display '2', not 8 (because although each symphony comprises 4 movements, and therefore, potentially, 8 tracks, we count 'folder plays', not 'track plays').
The Recordings (total) statistic is simply the number of rows in the ALBUMS table within the database. Note the subtle shift in terminology here: we speak of 'recordings' rather than (say) 'compositions'. That's because an entry in the ALBUMS table is made unique by reference to recorded music's primary key: composition name+distinguishing artist+year of recording. So, although there's only one Beethoven 5th Symphony, as a composition, there are different recordings of it by (say) Solti and Karajan... and Karajan recorded it at least twice, so the recording year is needed to distinguish between his separate attempts. So, I am shown with 12, 636 unique recordings... but at least 18 of them are different recordings of the same Beethoven 5th symphony!
Finally, Recordings not yet played is a count of those items in the ALBUMS table which don't have corresponding entries in the PLAYS table. That I've played Soltu's and Szell's Beethoven 5th doesn't mean I've played Klemperer's. Accordingly, Klemperer's recording of that work will be counted as 'not yet played', even though I've heard Beethoven's 5th as a composition more times than I've had hot dinners.
Note that there is no relation between Recordings (total), Play Count and Recordings not yet played. You cannot take the total number of recordings, subtract the ones not yet played and derive the Play Count, for example. Imagine a music collection consisting of just three recordings: Beethoven's 5th by Klemperer, Previn's recording of The Planets, and Britten's recording of Billy Budd. That makes 'Composers' equal to 3. It also makes the 'Recordings (total)' equal to 3. If I play the Planets nine times in succession, then 'Play Count' will be 9. 'Recordings not yet played' will be 2 (because I haven't played the Beethoven or the Britten). So my stats report would look like:
Composers: 3 Play Count: 9 Recordings: 3 Recordings not yet played: 2
Again, note that you cannot derive any one of these statistics by a combination of any of the others. 3 recordings minus the 2 not yet played leaves 1 (the Planets recording I've played repeatedly). You can't derive the 9 plays by reference to what I have chosen not to play, basically!
Bear in mind that if, like me, you have a substantial part of your collection 'not yet played', you can use AMP with the --unplayedworks switch (see below, 5.7.6), to force AMP to randomly select for play only those recordings (i.e., compositions recorded by a specific distinguishing artist in a specific year) which have never previously been played. Without that switch, AMP could well select to play afresh a recording that it has previously played several times before: that would increment the Play Count by 1 each time it does it, but does nothing to reduce the 'not yet played' count. With the switch, each new play is guaranteed to be of a recording that has never previously been played: that will increment the Play Count, but it will also decrement the 'not yet played' count by 1 each time.
5.7 Selection Overrides with a Database
The general principle when working with a database is that AMP will naturally and by default select a composer at random (provided he or she is not explicitly mentioned in an excludes.txt or is temporarily banned by virtue of a time-bar: see Section 5.4 above). Having then picked a composer at random, AMP will pick a composition written by that composer to play.
Usually, this sort of approach is fine, but there will be times when you want to say, 'nah. Stuff that. Play Salieri!' Or, 'Play something conducted by Karajan' or 'play something Maria Callas performs in'. When you want to override the default selection process used by AMP in this way, you can (from version 1.09 and above) supply four 'override switches', as follows:
5.7.1 The Composer Override
If you add --composer=xxxx to the command prompt when running AMP, you are telling AMP to play only music by composer 'xxxx', regardless of whether that composer has been excluded or time-barred. For example, amp --usedb --dbname=main --composer=walton will make AMP select something by William Walton for play. Note that the 'xxxx' value does not need to be complete, merely matchable, because AMP uses outer wildcards by default. AMP is also case insensitive, so --composer=britten will match "Britten" or "BRITTEN" or "bRiTtEn".
5.7.2 The Genre Override
The --genre=xxxx override switch forces AMP to play something of the specified genre. Thus--genre=opera will force AMP to play an opera of some sort. The composer will be chosen at random, and the composition will be chosen randomly after that -but it will definitely be an opera that gets selected! Note that any excludes.txt or time-bars will be observed. That is, if you specify to play opera, but Mozart is in your excludes.txt, or you played a Britten String Quartet at 9AM, then whilst you can guarantee that some opera or other will be played, you can also guarantee that no opera by Mozart will be picked at all, and no opera by Britten will be picked until at least 3PM (assuming the default 6-hour time bar is in operation).
5.7.3 The Performer Override
The --performer=xxxx override switch forces AMP to play something where the PERFORMER tag has been set to something specific.
For example, a 1966 Beethoven Symphony No. 5 recording might be by Herbert von Karajan conducting the Berlin Philharmonic Orchestra. If you follow this site's tagging guidelines, your ALBUM tag for that recording would be Symphony No. 5 (Karajan - 1966). The COMMENT tag would be Herbert von Karajan, Berlin Philharmonic Orchestra... and the PERFORMER tag (which stores the full name of the 'distinguishing artist' whose surname is embedded in the ALBUM tag) would be set to Herbert von Karajan.
In that case, supplying --performer=Herbert might well cause AMP to select that recording for play. A setting of --performer=Karajan would also do the job. Composer excludes and timebars are observed, however, so if you already played a Beethoven quintet at 9AM, a demand to play something performed by Karajan would not select a Beethoven Symphony recorded by him until at least 3PM (assuming the default 6-hour time bar is in use).
5.7.4 The Comment Override
Following on from that previous example, how would you go about forcing the playing of something in which the Berlin Philharmonic appears? Or an opera in which Maria Callas performs? The --comment=xxxx override switch takes care of that: it matches any text found within the COMMENT tag. So The --comment=berlin might work for the first example, and --comment=callas would probably work in the second.
Of course, as all the other override switches do, the value you supply is 'wild carded' so --comment=berlin might match a recording where Irving Berlin is playing the keyboard, for example. Similarly, --comment=callas might match a recording where Andrew MacAllastair was playing timpani.
It should be noted that all four overrides must have values supplied in double-quotes if they contain spaces. If you want to avoid that spurious match with Andrew MacAllastair, for example, then --comment="maria callas" could be used to get more specific.
Note that only one override switch can take effect at a time (except from version 1.12 and onwards -see below). If you supply multiple parameters, an order of precedence takes effect, as follows:
- composer
- genre
- performer
- comment
The composer switch takes precedence over all the others; the comment switch is over-ridden by any of the others. Hence typing --genre=opera AND --performer=callas in the hope of forcing the playing of an opera in which Maria Callas performs won't work. You'll definitely get an opera, because that's higher in the order of precedence than the performer switch, but there's no telling who will be performing in it. Callas might be, or she might not be: you cannot combine multiple overrides, basically.
Updated to add: The statement that you cannot combine overrides is and remains generally true. But from AMP version 1.12 and above, you are permitted to specify both the composer and genre overrides at the same time, and the effect will be that both take effect. Thus --composer=beethoven --genre=symphonic would, in versions prior to 1.12, get you some Beethoven, but whether it was a symphony or not was a matter of random chance. From 1.12 and beyond, you will definitely get to listen to a Beethoven symphony! You can still specify each override individually if you prefer; and if you use them at the same time as using the performer or comment switches, the previously-described rules of precedence apply: so composer+performer will simply get you the right composer with the performer ignored completely; and genre+comment will get you the right genre, but the comment filter will be silently ignored. And if you try combining composer+genre+performer or composer+genre+comment, the third filter is always silently ignored.
5.7.5 The Negate Override
Beginning with version 1.10 of AMP (released on 15th of February 2021), it's possible to add one further command line switch to the command you use to invoke AMP: --negate. It takes no arguments: it's just there or not. If it is there, then whatever override switches you've supplied reverse their sense.
In other words, whilst --composer=britten means 'play something written by Benjamin Britten', --composer=britten --negate means the exact opposite: play something NOT written by Britten.
A more useful example might be: --genre=opera --negate which means "don't play opera".
Every other rule about the override switches still applies when the negate switch is present. For example, if you negate a --composer override, the rule about excludes.txt and timebars being ignored still apply. And if you are using the negate switch with any of the other three overrides, the excludes.txt and time bars will definitely still apply.
From version 1.12, if you have specified composer+genre and additionally supply the negate switch, then you will be negating both filters equally. That is, --genre=symphonic --composer=beethoven --negate will gurantee that no Beethoven nor any symphonies will be selected (so you might get a Bach cantata or a Mozart opera, for example).
5.7.6 The Unplayed and Unplayedworks Overrides
In versions 1.20 and upwards, additional overrides were added to AMP: --unplayed and --unplayedworks. The former forces AMP to randomly select works by composers that have not previously been played. The latter forces AMP to randomly select a recording that has not previously been played.
The difference is perhaps a bit subtle, but fundamentally quite clear. Let's say you go buy a new recording of Beethoven's 5th Symphony, under the baton of a hot new conductor called Simon Prattle. It is likely that you have played lots of other works by Beethoven before this: so Beethoven as a composer is not 'unplayed', but this new Simon Prattle recording is. Let us say, too, that you took the purchasing opportunity also to pick up a recording of Symphonietta Rustica by Eugen Suchoň, who you'd never even heard of before now. That makes Eugen Suchoň an unplayed composer, as well as the Symphonietta being an unplayed recording.
In the first case, of the Simon Prattle recording, running AMP with the --unplayed switch won't help you get that new recording played at all. Since Beethoven has been played a bazillion times before, he's not an unplayed composer and therefore the switch cannot help select Prattle's new recording of the 5th symphony. However, it is likely that --unplayed will trigger Eugen Suchoň for play, because he's a brand new composer to your collection and has never had anything selected for play before.
On the other hand, running AMP with the --unplayedworks switch will help get the Prattle recording to play (because it's a recording that hasn't previously been played), and it will also get the Symphonietta Rustica get played -because that's a brand new recording to the collection, too. The only trouble is that both the Prattle and the Suchoň are equally unplayed recordings! So, AMP will pick one or other of them at random to play. Neither switch, on its own, can mandate the playing of a particular composer or recording that hasn't previously been played, in other words.
6.0 Album Art
SinceAMP Version 1.05, AMP has been able to display the album art associated with the first FLAC track found in a folder as it plays that folder-worth of music files. It is displayed in a separate window from where AMP itself is playing. This window can be moved and manipulated like any normal graphical window -except that if you close it, you cannot re-open it. You'll have to wait until AMP starts playing a new piece of music and then, at that point, that new music's album art will be displayed in a fresh window in its turn.
Note that album art can only be displayed if your Linux distro has ImageMagick installed. This is the jack-of-all-trades image manipulation software that is, in fact, commonly installed by default on most Linux distros these days. If yours doesn't have it installed already, the software is usually in most distro's standard repositories, so it's generally not hard to install if needed.
Whilst AMP checks to see if ImageMagick is available, it doesn't warn you if it isn't. The reasoning is that the display of album art is not really part of AMP's mission statement, so it shouldn't fail to run if it can't find it, but should instead just silently know not to attempt to display anything.
However, if ImageMagick is installed, then AMP will display album art by default. If you'd prefer not to see album art, a run-time switch is provided to stop it being displayed: --noart.
Be aware that Ubuntu does not have Imagemagick installed by default (last time I checked) and that even when you do install it (sudo apt install imagemagick), AMP still cannot correctly display album art because it doesn't install the magick executable. Fortunately, you can resolve this on Ubuntu (and perhaps on other Linux distros I haven't tested) by issuing the following command:
sudo ln -s /usr/bin/display /usr/bin/magick
The final 'k' in 'magick' is not a typo! Once that soft link is in place, album art will display in Ubuntu as it would do in other distros like Manjaro (which doesn't need this workaround!)
By default, in versions 1.05 - 1.10, if album art was displayed it would be displayed as an image 900x900 pixels in size, no matter what the original size of the album art might have been. In version 1.11, this changes: the default size is now 600x600 pixels. In version 1.11, however, a new run-time switch is provided that allows you to control the size of the album art: --artsize=xxx, where 'xxx' should be one of large, medium or small. Large means 900x900; medium is 600x600 and small is 300x300 pixel display. If you don't supply an --artsize parameter at all, or if you supply one set to an invalid value (such as --artsize=humungous), then 'medium' kicks in as the default, and hence you get a 600x600 display.
Bear in mind that the album art display function only checks the first FLAC file found in a folder. If, for some reason, the first file has no album art embedded within it, but the other 68 tracks do, then: tough luck, really. No album art will be displayed for the duration of the play of those 69 tracks!
7.0 Some Technical Issues
7.1 Alsa
You should be aware that AMP is written to direct its output to the default ALSA device. The reason for that is that I wanted AMP to have as little between it and the audio hardware as possible. It's for this reason that there's no volume control in AMP, for example: having one requires that the software 'take control' of the audio stream and manipulate it, rather than merely pass it directly through to your sound card or DAC hardware.
For the most part, that AMP is directing its output to an ALSA device. But be aware that a limitation of ALSA is that you can only have one program writing to the audio hardware at a time. So if AMP is playing, and you try playing a Youtube video, or something in VLC, you may well find those other programs appear to 'hang'... because they're queued up, waiting to access the audio hardware behind AMP. Terminating AMP will give those other programs a chance to play after all. Similarly, if you're playing a Youtube video first, and then try running AMP, you may well find AMP spins its 'playing' spinner, but no sound comes out: that's just AMP queuing behind Youtube. Kill your Youtube browser tab and you'll usually find AMP springs into life shortly thereafter.
If you hear nothing when AMP clearly claims it's playing something, you may need to configure Alsa, which is something rather out of scope for this article! You could start by running alsamixer however, which is part of the alsa-utils package.
7.2 Parallelism when Randomised Playing
When AMP is run in Remote Mode and is implicitly asked to perform a randomised selection of compositions from a large music collection, it will naturally take time to evaluate that collection and pick something at random from it.
To speed things up in this regard, AMP parallelizes the initial scan through your music collection folders. By default, it parallelizes to the maximum degree permitted by your CPU. That is, if you're running a 4-core CPU with hyper-threading (or 'simultaneous multi-threading' if you're not using an Intel CPU!) enabled, AMP will use 8 threads to scan your library before making a random selection.
If you wish to artificially restrict how many threads AMP can use at this point, you can set an environment variable called AMP_THREADS=x, where 'x' is a number lower than the number of CPU threads you can actually use. (If you set x higher, AMP ignores it and reverts to its default behaviour and uses the maximum threads of which your CPU is physically capable.
Setting a persistent environment variable is most simply accomplished by editing $HOME/.bashrc, and adding to the end of it this line:
AMP_THREADS=x
...making sure to leave no spaces around the equals sign -or indeed anywhere else within the text (and setting 'x' to an actual number, rather than just the letter x!) Save the edited file and reboot your PC: the new variable will then be picked up automatically and be applied for all future runs of AMP thereafter.
Bear in mind that parallelism only affects randomised searching for music to play: once music begins to play, AMP is pretty much a single-threaded application and is extremely low on memory and CPU resources. This sort of situation is typical on my PC as it runs some rsync housekeeping jobs in the background and AMP is busy playing music:
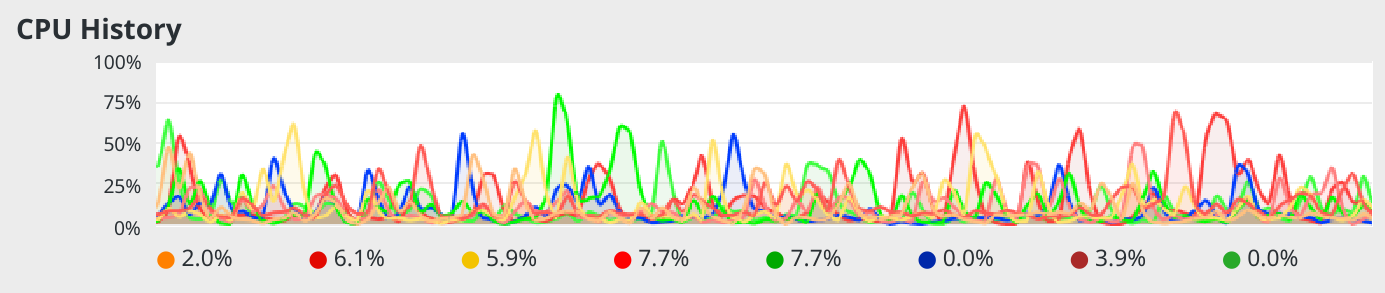
Even on feeble PCs, you should barely be nudging into double-figure percentage utilisation when using AMP!
7.3 Aliasing
Finally, if you are like me and generally want to use AMP's random-play feature to keep your listening habits diverse and broad, but occasionally want the ability to run AMP in non-random mode, you should consider creating an alias for amp in your $HOME/.bashrc. For example, here's mine:

Here, I have two aliases "ampr", which runs AMP in 'Remote Mode'; and "ampl" which runs it in 'Local Mode'.
So, by typing ampr at the command prompt, all by itself, I get a randomised single play from somewhere in my entire music library.
And if I type ampl at the command prompt, I'm really just running the plain vanilla 'amp' command (but at least the alias name makes it clear I'm deliberately choosing to run it in local mode!)
Having the two aliases means I can invoke amp in whatever mode I fancy, randomised or non-randomised, as the mood takes me, and without having to type a long 'musicdir' path if I want the randomised fun stuff!
If you're going to use a database -or even multiple databases- then your aliases need to take that into account, too. Thus, given my recent upgrade to AMP version 1.02 (the first one to allow the use of databases) my .bashrc now reads as follows:

If I type ampr, I'll be playing my main music library at random, using a database called 'main'. If I type ampo, I'll be playing my overflow music library at random, using a database called 'overflow'. And if I type ampl, I'm still just playing music locally, without randomisation, assuming I've cd'd to a folder full of FLAC files in the first place.
7.4 Update Checks
You should periodically check this website to see if the latest version available for download is newer than the version you are running. Starting with version 1.14, AMP can now perform its own update check if it is invoked with the --checkver runtime switch. If a newer version is detected, you'll be asked whether you want to go ahead and upgrade. If you say 'y'es to that, then the newer version is automatically fetched from this site, made executable and copied into the /usr/bin directory (this last step will require -and prompt for- sudo/root privileges). Any other runtime parameters or switches you may mention are ignored if the --checkver parameter is present: once the version check (and upgrade, if necessary and agreed to) is complete, the program exits and will need to be re-run without the --checkver parameter for normal music playback duties to resume.
For example:

...here I have tacked on the '--checkver' parameter to a bunch of other parameters I usually use to play the music of Respighi. But when I press [Enter]:
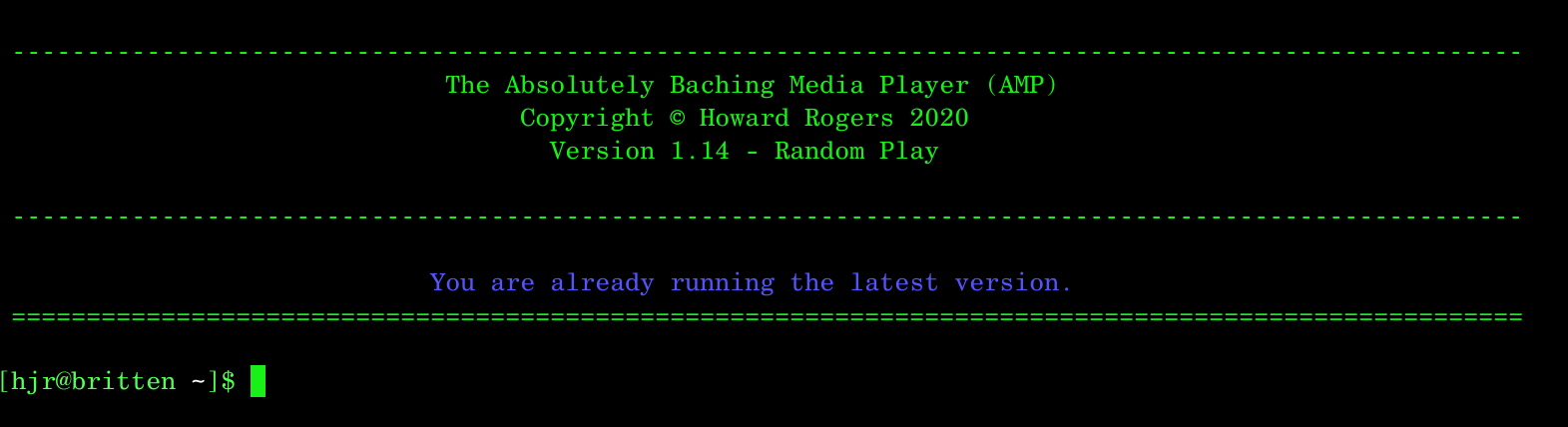
...the version check takes place (on this occasion, I pass in blue, so my running version (1.14) has been detected to be the latest version), and then I am simply dumped back at the command prompt. All that stuff I had additionally supoplied about 'minduration this, composer that' is simply ignored.
This is what happens if the script detects that you are not running the latest available version of the software:
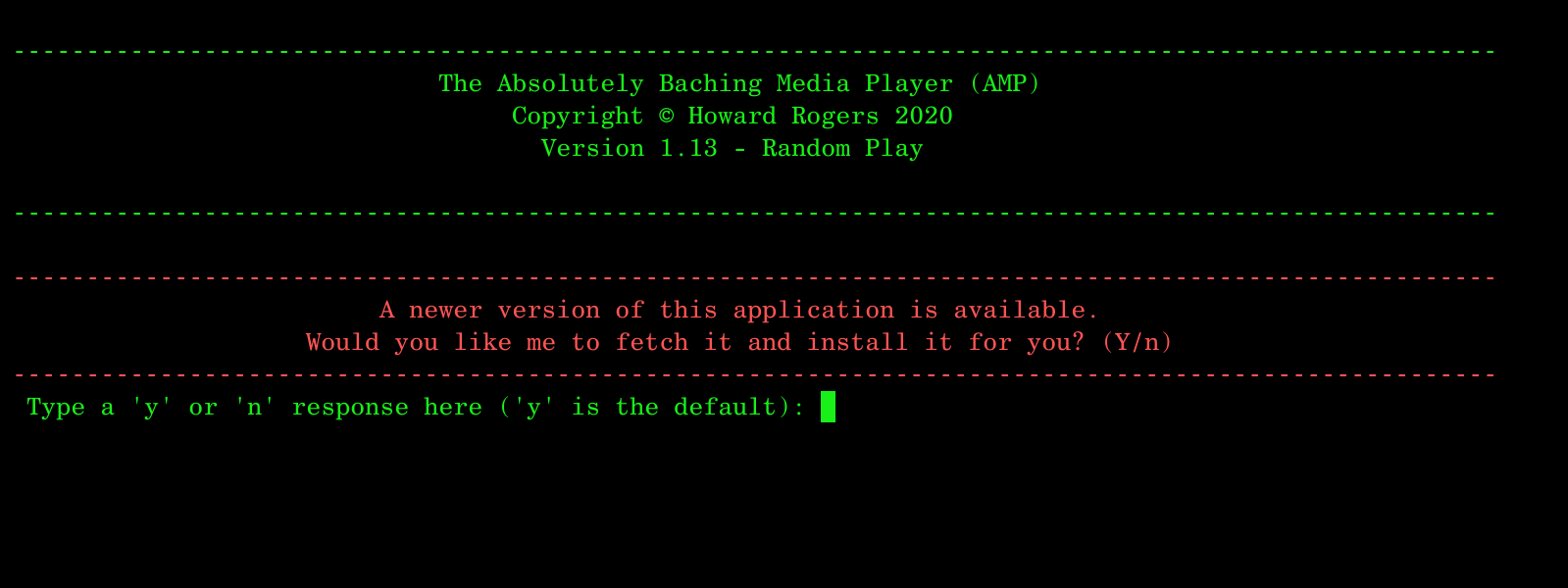
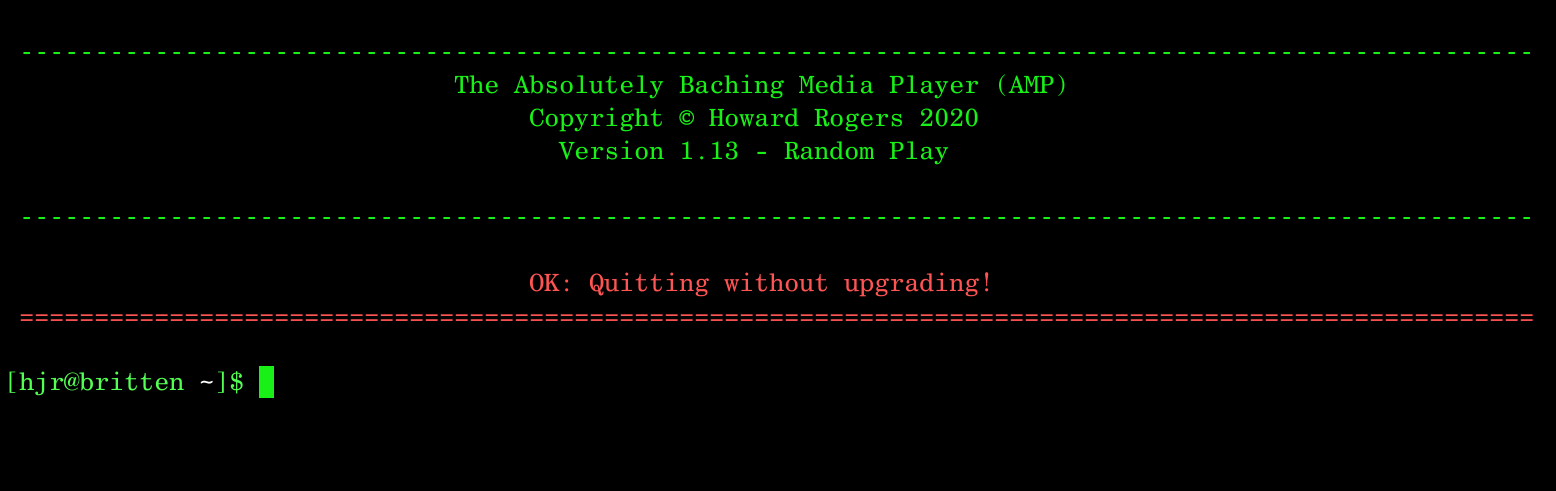
It detects (in red text) that an upgrade is available and therefore asks you whether you wish to upgrade. The correct answer here is either 'y' or 'n' -and 'y' is the default. So if you just press 'Enter', that counts as saying 'y'es. If you type 'n' (or indeed anything other than 'y'!), it is assumed you do not wish to upgrade. If you do not upgrade, the program simply quits:
And if you agree to upgrade, you are simply prompted for your sudo password (i.e., the password you use to acquire root privileges):
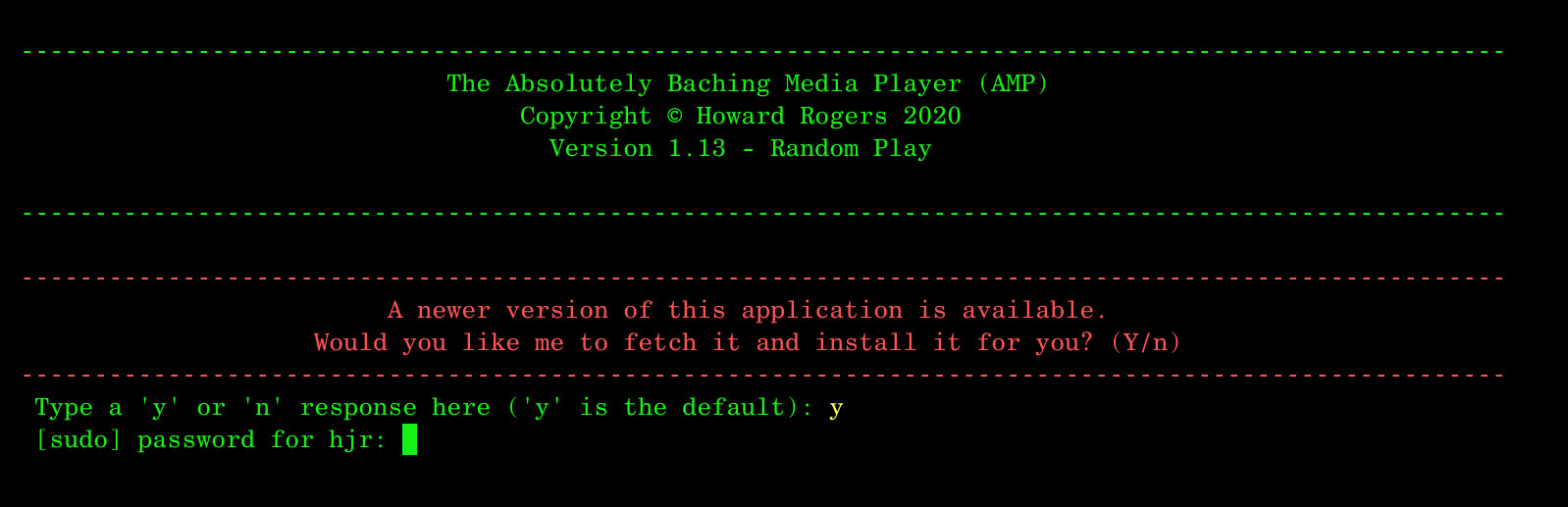
Once the password is supplied, the upgrade happens pretty much instantly thereafter.
From the foregoing, it should be obvious that you can only use this --checkver functionality if (a) you have access to the Internet when you invoke it; and (b) you are allowed to use sudo to escalate your user privileges to those of root. If you're not in the sudoers file, for example, then this functionality will not function correctly. It is suggested that you run AMP with --checkver every month or so, just to make sure you're not missing out on crucial bug-fixes or new bits of functionality. If you don't like the results of an upgrade, remember that you can always manually download the previous version of AMP and copy it into the /usr/bin folder and thus achieve a rollback of an upgrade without too much drama.
8.0 Housekeeping and Legal Stuff
Frequently Asked Questions (FAQ)
The AMP FAQ can be found on this page.
Author
AMP was devised and written by Howard Rogers ([email protected]). However, it uses a lot of opensource software to actually do anything useful, so full credit to the developers of (for example) ffmpeg. Particular thanks goes to Pachanka for developing the 'moc-scrobbler' (where "moc" means 'music on console' (i.e., at the command line). Without lifting that pretty much verbatim, AMP could not scrobble successfully.
License
AMP is copyright © Howard Rogers 2020 but is made available freely under the GPL v2.0 only. That license may be downloaded here. The scrobbling components are Copyright © 2018 pachanka and are licensed under an MIT license.
Bugs Tracking, Feature Requests, Comments
There is no formal mechanism for reporting and tracking bugs, feature requests or general comments. But you are very welcome to email your comments, complaints or suggestions to [email protected].