1.0 Introduction
 In any data-based application, the key to flexibility, speed and extensibility is to be able to identify, with the fewest possible pieces of information, an utterly unique way to find a single piece of data in which we're interested. The combination of attributes which uniquely identify a data item is then called the 'primary key' of that particular data set.
In any data-based application, the key to flexibility, speed and extensibility is to be able to identify, with the fewest possible pieces of information, an utterly unique way to find a single piece of data in which we're interested. The combination of attributes which uniquely identify a data item is then called the 'primary key' of that particular data set.
Technically, the problem of how to find the minimal primary key to retrieve needed data is a branch of "information theory" -but this detail needn't detain us unduly and I promise to try to make the discussion as un-technical as possible. So long as you remember that "primary key" means "least information needed to retrieve the full set of data", you're doing fine!
In any event, the point of this article is to examine the question: If we are to catalogue our music so that it can be accessed flexibly and quickly, what is music's 'primary key'? Having identified it, do the practical restrictions placed on us by common music playing software cause us to re-think it in any way?
In this article, then, I'll explain what music's primary key is and how the distinction between 'primary' and 'secondary' types of data about music is an important one to remember as you practically go about cataloguing and classifying a large music collection.
2.0 An example with Books
To begin with, I'd like you to think about how you identify a given instance of a book or novel? (I don't mean distinguish between different copies of a book; just between two different novels in principle). In many cases, you might think 'book title', since you would not then confuse A Tale of Two Cities with, say, Dombey and Son -and, in many cases, this would indeed be unique. But therein lies a trap, because book titles are only usually unique, but they don't have to be (see this article for some good examples of where book/novel titles have been duplicated (or nearly so) over the years). First rule of information theory: if it's ever possible for a data attribute to be non-unique, it cannot on its own be used as a true primary key. It doesn't matter if, in a particular set of circumstances, the data attribute is unique. That is, I walk into a specific book shop and find that they don't have a copy of Kate Acker's Great Expectations, so in that shop, book title is unique. No matter. The fact is that, theoretically, the title might duplicate in another bookshop. Therefore, book title cannot be a primary key candidate.
To work around that requirement, perhaps, we'd think, "Add in Author. The combination of Author+Title must surely be unique?" Certainly, Charles Dickens+Great Expectations is now easily distinguished from Kate Acker+Great Expectations, so the combination of Author+Title seems unique enough to warrant being thought of as a book's 'primary key'.
However, we must again consider the context within which a primary key will be used. For example, consider my own bookshelves at home: I'm lucky enough to own an 1848 first edition of Dickens' Dombey and Son. It's lovely to own... but it's got lots of typographical mistakes, the pages are quite brown and the font used is rather old-fashioned. So whilst it's nice to own it, I never actually read it! For that, I have the Penguin Classics paperback edition...at which point, my bookshelves violate the uniqueness of Author+Title, for there are two Dickens+Dombey and Sons on my bookshelves!
There are various workarounds possible. The first one that springs to mind is to add the publishing house. OK, let's try that then: my first edition appears to have been produced by Bradbury & Evans; the paperback by Penguin.
Charles Dickens+Dombey and Son+Penguin does now seem distinguishable from Charles Dickens+Dombey and Son+Bradbury & Evans. Primary key re-discovered, then!
Well, maybe not so fast: Penguin have re-printed their version of the novel many times over the years, I'm sure. The one I have is dated 1995... maybe there's a 1996 printing of the same edition? It's unlikely someone would have both copies on their bookshelves at the same time, of course... but if it could happen, then we cannot consider Author+Title+Publisher a truly good primary key candidate. Maybe we'd have to go for Author+Title+Publisher+Year instead?
In this manner, we could continue to explore and add new pieces of information into our primary key candidate until we hit upon some combination or other that is truly and forever unique: that would then cease to be our primary key candidate, but would become our actual primary key.
I won't pursue this particular line of thinking further, because I frankly don't know enough about the printing and publishing trade to really tell you what an ideal primary key would end up being! I really just wanted to show you that your first thoughts on a likely primary key candidate are seldom the last word on the subject: as the scenarios and possible situations in which your data model must work proliferate, so what seemed like good keys turn out not to be so good at all. And what might work well in one situation might fail badly in another (for example, consider if your bookshelves do not have two versions of Dombey and Son on them, but mine do: what you decide is an excellent primary key might then be a disastrous choice for me in my environment).
I also wanted to make the point that what we think of as candidate primary keys have no relation to other things we might want to find a novel by. I mean, for example, that I may well think to myself one morning "I wonder what novel it was that had the line 'It was the best of times; it was the worst of times'. That is an entirely valid question -meaning, it's an entirely legitimate thing to want to search for. But 'by their first lines' is not a suitable way to organise the fundamental ordering of a catalogue of books (because they could, plausibly, duplicate... and first lines are always going to contain more words than the terse combination of author+title+publishing house name. Remember: we are seeking to minimise the criteria that define uniqueness). The need to order a data set in such a way as to find unique items comes first; the ability to search data for any random thing that springs to mind is a secondary (though important) consideration. The requirements of the latter should not dictate how we determine the former.
3.0 Natural and Synthetic Primary Keys
I also want to pause at this point to say that what I've been describing is the finding of a natural primary key: that is, a key using pieces of information (such as an Author's name, or a novel's title) which make natural sense to humans. There is often an easier way to devise a primary key, however: use a synthetic primary key. That is, pick a piece of meaningless data which makes no real sense in the outside world but which you know, because you invented it, will be unique for every data item and label each data item with it. For example, every time you open a spreadsheet, you're looking at a synthetic primary key in the far left-hand column of the screen: the row numbers start at 1 and increment sequentially thereafter. Every row in the spreadsheet is therefore 'addressed' (and can be referenced by) a guaranteed-unique number which in and of itself has no meaning or significance to the data you choose to store in the spreadsheet's cells.
Books essentially have such a synthetic primary key ready-made for them these days, too: the ISBN (the International Standard Book Number). It doesn't identify every individual copy of a book uniquely, but it identifies a particular printing/edition/variation of a book. So Penguin's print of Dombey and Son will have a different ISBN to Random House's print of the same title, and so on. Of course, the ISBN was invented after Dickens died and my first edition of the novel accordingly doesn't actually have an ISBN... which kind of scuppers using it as a truly universal primary key! But if we said 'what's the primary key of books printed after 1970?', the ISBN would be a fine candidate.
Anyway, the point it that synthetic primary keys are easy to make 'guaranteed unique' and completely immutable. But, being synthetic, they lack meaning for real people! You don't often go into a bookshop and say, "Do you have a copy of 968-3-16-148710-0, please?", for example! Thus, whilst they are great for defining uniqueness, they are pretty lousy for using in real life. As such, I want to restrict our thinking only to natural candidate primary keys from now on.
4.0 Printed Music's Primary Key
So now let me re-phrase my initial question: what is the minimum combination of attributes that will uniquely identify a given piece of printed or hand-written music in natural form? I don't mean CD or DVD music at the point: I simply mean, how do I tell the difference between this symphony and that one, or this piano concerto and that one?
Well, it cannot simply be the name of the composition. Here's a Symphony No. 5:

... and here's a completely different Symphony No. 5:

How can we tell them apart if their names are identical? I think it's easy to see that composition name is not and can never be a candidate to be music's primary key, therefore.
But what if we add in the Composer's name? Would Beethoven+Symphony No. 5 be unique and forever distinguishable from Shostakovich+Symphony No. 5? I think it might well be. The questions to ask to make sure would be: did a composer ever compose a piece of the exact same name twice or more? Off the top of my head, I can't think of an instance where that happens. Vaughan Williams certainly wrote several pieces called 'Norfolk Rhapsody', as a possible example... but he numbered them as he did so, so the titles of them tend to be 'Norfolk Rhapsody No. 1', 'Norfolk Rhapsody No. 2' and so on. Similarly he wrote a couple of pieces which are called 'Fantasia' -but one is 'Fantasia on a theme by Thomas Tallis' and one is 'Fantasia on Greensleeves', so the full titles of the pieces do end up being unique, I think.
So: I would at least propose Composer Name+Composition Name to be printed music's candidate primary key!
Unfortunately, that won't do if you think of symphonies (for example) being constructed from separate and individual movements ...and if we now redefine our discussion's boundaries a little to be 'how do we distinguish between different parts of printed or written music' (just as, in the book example, I re-defined the scope of the discussion to take into account individuals' bookshelf contents rather than 'novels in the abstract').
Beethoven's Symphony No. 5 is comprised of four individual movements, for example... and Composer+Composition doesn't distinguish any of them from each other. But if you add one more element to the candidate primary key -namely, movement name- than I think we're getting close: Beethoven+Symphony No. 5+Allegro con brio is now easily distinguished from Beethoven+Symphony No. 5+Andante con moto, for example. (Notice that I've assumed the use of the composer's own tempo marking as a movement's "name". That wouldn't be true of the separate arias and recitatives in an opera, of course: but in the case of that sort of music, maybe we'd agree that the first line of the libretto text for each aria or recitative would count as the 'name'? Either way, let's just assume for now that such a 'name' is available for all parts of all compositions and worry about how we specifically decide on the name of a 'part of a composition' until later).
Thus Composer Name+Composition Name+Movement 'name' is a promising new candidate primary key. But, just as we did with the books example, we must ask questions of this candidate and test whether it is truly and universally unique! Is it?
Well, it is if you only play the symphonies of Beethoven, Shostakovich and the fantasias of Vaughan Williams! However, Mozart (just to cite one example!) had a habit of not getting terribly imaginative with his tempo markings! Consider, for example, Mozart's Symphony No. 11. It has movements with tempo markings of, respectively, Allegro, Andante and Allegro: how are you going to tell the first and third movements apart, if all you are using to distinguish them is their tempo markings... and those are identical?
Well, this one is not easy to fix, to be honest, without resorting to a little synthetic key trickery! If we add a movement number into the mix, we'd end up with:
Mozart+Symphony No. 11+1+Allegro and Mozart+Symphony No. 11+3+Allegro ...and those two things are finally unique and distinguishable from each other.
So now our primary key candidate is:
Composer+Composition+Movement No.+Movement 'title'
I'll pause at this point to mention that this is actually not a robustly good data model from a strict information theory point of view, since the last component of that candidate key is actually and merely what is called 'derived information'. If you tell me "Mozart+Symphony 11+Movement 1", I actually already know (or, at least, could look up in Wikipedia to find out) that the movement's tempo indication is 'Allegro'. And similarly, mentioning 'movement 2' would tell me, by implication, 'Andante'. Technically, there's no need to include derived information in a primary key candidate, since the piece of data which gives us the ability to derive that extra piece of data is already sufficiently unique.
Put it another way: by introducing movement number into the mix, we've technically done the same thing as quoting row numbers in a spreadsheet: it's already unique; adding the movement name after that doesn't actually help us get 'more unique' than we already are!
Thus, technically, we only need three pieces of data in our primary key candidate: Composer+Composition+Movement Number. Would these three pieces of information be a good primary key candidate, though?
Technically, yes, I think so. But... but... no-one of mortal woman born actually remembers the tempo markings associated with every one of Haydn's infeasibly large collection of symphonies. If I said "Haydn, Symphony 34, Movement 2", would you happen to know in passing that I meant the Allegro from that symphony? Probably not. Is knowing the movement's tempo marking useful and helpful? Yes, it is. So, practically, though it's not strictly needed, I'd definitely want to include 'movement name' in the proposed primary key. Strict disciplinarians of data modelling would call this 'a flaw in the normalization of the data', but phooey to them anyway!
So, four data attributes are practically required for music's primary key: Composer+Composition+Movement Number+Movement Name.
And I think that's a good primary key candidate for music in its printed or hand-written form. With it, I think we can distinguish between a Haydn symphony and a Beethoven one; or a Beethoven one and a Shostakovich one. We can also tell the 15 Shostakovich symphonies apart from each other. And we can tell Shostakovich's Symphony No 1's Allegro movement (movement 2 of that symphony) is different from Shostakovich's Symphony No. 10's Allegro movement (also movement number 2 of that symphony). Some part of the Composer+Composition+Movement number+Movement name combo is always unique in all those situations, so I think it's not just the candidate primary key, but the actual primary key for music.
5.0 Recorded Music's Primary Key
The primary key for printed (or hand-written) music works fine, I think... until we get to recordings of music!
For though Beethoven wrote only one Symphony No. 5, it's been recorded about 12,200 times by assorted conductors and orchestras around the world in the 90 years or so since recording technology made that sort of thing possible. So if you want to tell Furtwangler's recording of Symphony No. 5 apart from Karajan's, our earlier primary key is not up to the job: Composer+Composition+Movement Number+Movement Name is no longer capable of telling one recording apart from another.
Clearly, what we need to add to the mix is the conductor's name. If we had:
Beethoven+Symphony No. 5+1+Allegro con brio+Furtwangler
...we'd easily tell that apart from
Beethoven+Symphony No. 5+1+Allegro con brio+Karajan
Right? Well, we would...except that the two conductors I just mentioned had a habit of recording the same symphony multiple times! Karajan, for example, recorded Symphony No. 5 five times in less than 40 years. How do you tell his 1950s recording of it apart from his 1961/2 recording? The obvious answer would be: stick a recording date in there somewhere! Meaning that our candidate primary key for recorded music would now be:
Composer+Composition+Movement Number+Movement Name+Conductor+Recording Year
The equally obvious question to ask at this point would be: did Karajan (or any other conductor) record the same composer's symphony in the same year more than once? Because if it were even possible for them to do so, this would not be a suitable primary key candidate. We could, however, guarantee that our primary key would cope even with that unlikely situation by borrowing from the synthetic world of the spreadsheet once more. Make the candidate key the following:
Composer+Composition+Movement Number+Movement Name+Conductor+Recording Year+Recording Number
...and you could distinguish Karajan's recording of Beethoven's 5th in March 1964 from that he (hypothetically) made in April 1964, for example:
Beethoven+Symphony No. 5+1+Allegro con brio+Karajan+1964+1 ...versus...
Beethoven+Symphony No. 5+1+Allegro con brio+Karajan+1964+2
...seems unique enough to me! So 7 seems to be the minimum data items needed to act as recorded music's primary key.
6.0 An Intrusion of Practical Considerations
I want to pause again at this point. We now have arrived at an answer to our earlier question: to uniquely identify any individual track (i.e., movement) of an LP or CD, we appear to be proposing a 7-component natural primary key. There's nothing intrinsically wrong with that, speaking technically... but the longer your primary keys, the harder it is to work with them efficiently in practical applications.
Take, for example, the Clementine media player (it happens to run on Apple, Windows, Linux, Raspbian and probably a few other operating systems besides, so it's a reasonable approximation for a 'universal' media player). How does it organise it's principal display of music? Like this:
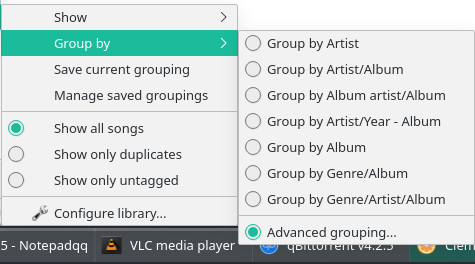
Seven built-in grouping options are available (select any one of them and that also becomes the default sorting order of your music library display). Do you notice how it only provides, at a maximum, three components? Artist/Year - Album is one such and Genre/Artist/Album is another. But nowhere is there a listing of a 4-option grouping function, let alone a 7-option one!
The Artist/Year - Album option is, in fact, broadly equivalent to our Composer+Recording Year+Composition Name elements of our proposed primary key, though with the component bits re-arranged and with some missing, so we could usefully group (and sort) by three of our seven primary key components. Which is great -but means the remaining 4 would end up not being a grouping or sorting consideration, and that would break the functionality of the player. Looks like we're out of luck then, practically! Unless... Is anything available to fix this under that 'Advanced Grouping' option?
Turns out... not really:
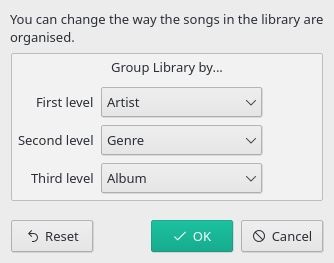
Here, you certainly get to choose which three data items to group and sort by, but three element grouping is still your limit.
This would seem to be a failing in Clementine -but you'll find most media players do the same sort of thing, largely because if they did allow you to sort and group by all seven primary key elements, the display would end up being an unholy mess. Think of it: you'd have a list of composers; click on one of those and you'd get taken to a list of compositions by that composer; click on one of those, you'd get taken to a list of all the movements belonging to that selected composition and so on. You'd have to click seven times before you got to a unique track of recorded music that could actually be played. Functionally, therefore, using such a long composite key would be a bit of nightmare.
Yet, theoretically, a 7-segment primary key seems to be necessary.
Is there a resolution to this apparent paradox?
7.0 The Solution!
Summing up: We need 7 data elements to uniquely identify any specific piece of recorded music (down to the individual movements making up a symphony or concerto, or the individual arias or recitatives making up an opera, or the individual songs in a song-cycle). But, functionally, we need to restrict ourselves to just three. To cope with this functional 'restriction of three', we will need to combine some of our separate data elements into a single data element. We should also remember that some of our primary key elements are actually derived information -so, strictly speaking, they don't need to be in the primary key at all.
So first, let's prune out the derived information:
Composer+Composition+Movement Number+Conductor+Recording Year+Recording Number
...gone is the Movement Name as a piece of plain text. We're back to thinking just in movement numbers (though we'll always want to see plain text names, we don't need to think about them further in this grouping/sorting discussion of the contents of a proposed primary key). Now we're down to just 6 key data elements -though that's still three more than we are allowed.
So now it's time for some combinations! If we move the conductor and recording year details up the hierarchy, we can achieve a useful bit of concision, like so:
Composer+Composition [Conductor+Year+Recording Number] + Movement Number
By this, I mean that when we store our composition names, we no longer name them strictly accurately from the composer's point of view. Instead, we make up a composition name which is a composite of the composer's chosen name, plus the conductor and recording year and number. In other words, we'd no longer be dealing with Symphony No. 5, but with Symphony No. 5 (Karajan, 1962, #1) as a 'composition name'. It still is unique and visually distinguishable from Symphony No. 5 (Karajan, 1962, #2) as recordings, so the functional aspect of our 7-piece primary key is still there... but now we only have one composite data element standing in for duty instead of four separate ones.
My terminology for this maneuver is called "Adding the distinguishing artist details to the strict composition name". The "distinguishing" artist is not the same thing as a "distinguished" artist, by the way: the conductor or violinist or whoever might be a complete bozo with all the music performance skills of my cat, so not at all distinguished. But so long as his or her name is there, together with a year and recording number, it will act as a usefully distinguishing name!
I think you will find that every recording without exception will need a 'distinguishing artist': there are just so seldom truly unique recordings of a work these days. Every composition seems to end up being recorded at least 2 or 3 times! The subtler point, however, is that you may not have multiple recordings of a work... but your data model still needs to reflect the fact that, one day, you might end up with multiple recordings. So, you might think, "No, I only have the one recording of Turandot: it's unique in my collection, so I only need to mention 'Turandot'". But this is short-sighted: one day, you'll buy another version of Turandot because of a better soprano, or better recording technology... now you have a differentiation problem! So, even when you, personally, do not now presently need to distinguish between different recordings of the same piece, your data model should be used consistently, and you should always specify a distinguishing artist name in the composition name.
It does, of course, now mean that our music library will not contain "true" composition names -because extra components will be stored in the 'true' composition name. So let us simply agree to call this hybrid the Extended Composition Name.
The key point is that by constructing this extended composition name, we've just reduced the number of separate components required in our primary key candidate for recorded music to only three elements: Composer Name+Extended Composition Name+Movement Number. Clementine can cope with that as a default sorting and grouping arrangement: so can every other music player on the planet! What's more, it means there will never be more than three clicks needed to start playing a unique recording of something.
Job Done! ... Or is it?!
8.0 A Modified Solution: Bring on the Genre!
Hold on a second, though. Whilst the scheme just outlined will work, it will get quite "chunky" at times. Benjamin Britten wrote only 93 published pieces in his lifetime, which is manageable. But J.S. Bach wrote over a thousand of them, which isn't. Mozart wrote over 600 of them, which is also unmanageable as an undistinguished lump of music!
What I'm getting at is that though we have defined a technically usable and 'correct' primary key for recorded music, it has other practical problems. Namely, that if we sort all of a composer's output into a single sorted list by extended composition name, some composers are going to have enormously long lists of compositions ...and some won't. Trying to navigate your way through at least 1000 items of Bach's output as a single list of compositions is not going to be pleasant! If you want to listen to a Xylophone Concerto and have to wade throgh 200 Alto Arias to get there, that's not a navigable music library!
What you practically need is to sub-divide a composer's output in some meaningful way: and I'm going to suggest that you chop it up by the specific 'genre' it belongs to. By this I mean you can listen to pieces by Bach (say) and declare them to be 'an organ piece', 'a choral piece', 'an orchestral piece' and so on. For Britten's output, you might divide the compositions into 'choral', 'keyboard', 'concerto', 'vocal', 'opera', 'radio & film' or whatever other musical sub-division makes most sense to you.
I've prepared a list of the broad genre classifications I would recommend elsewhere. The proposals aren't academically rigorous: I'm not proposing you split your opera seria from your opera buffa, for example: just 'opera' as a broad classification is more than sufficient for all cases that I can think of! In short, we're not trying to prove how musicologically educated we are: we are simply trying to minimise the amount of scrolling that has to take place when we want to play a specific piece of music.
Doing things this way allows you to sort and group your recordings in the following manner:
Composer+Genre+Extended Composition Name+Movement Number
It allows you to click Bach->Cantatas and now you'd swiftly be able to find BWV 67, because it's not embedded in a list of 1100 other compositions, but appears in a list of only around 220 cantatas. Adding the genre into the mix isn't technically needed to uniquely identify a specific recording, in other words... but it makes it practically a whole lot easier!
Now, you will probably have worked out already that the genre is merely 'derived information': if you tell me the composition name is 'String Quarter No. 3', I already know it's a chamber work, without that needing to be spelled out. Data purists would therefore correctly contend that the music's genre should not be part of a primary key, since it's dependent on something that's already there (namely, the extended composition name). Purity must go out the window, however, when practical considerations arise: and in this case, the need to 'chunk up' the large output of certain composers into manageable sections outweighs concerns about the derivative nature of the genre data item. So genre stays in!
But surely I've just made our primary key four data items long again... and earlier I was crowing about how good it was that I'd got it down to three! Isn't the extra data item going to break lots of music players?
No, is the short answer to that, and to explain why, take a look at this screenshot:
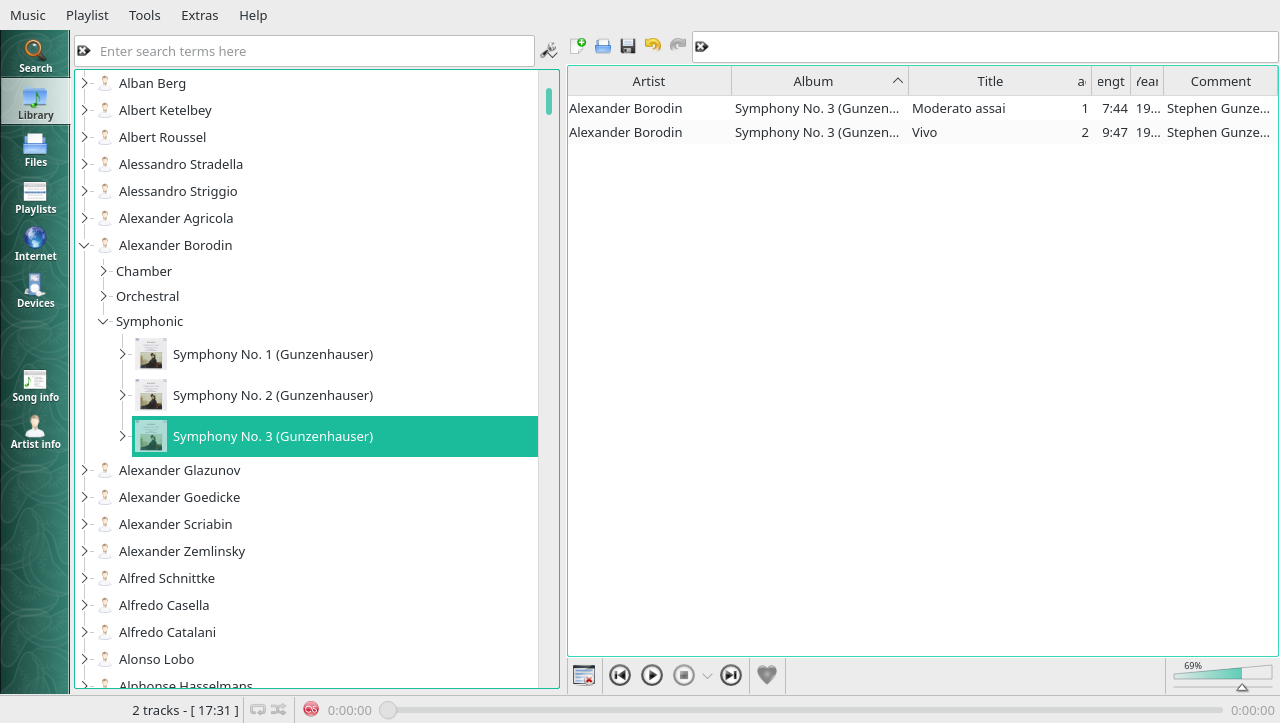
The list on the left-hand side of the screen is handling the first three of our primary key requirements: composer name is displayed first. Within that, we see different genres. And within the Symphonic genre in this specific case, we see the various compositions with their extended names (including the name of their conductor). But how is the fourth element being handled?
Well, look on the right-hand side of the screen. The individual movements of a selected symphony are listed in track (i.e., movement) number order.
Most media players will do things this way: the tracks within a selected recording will be displayed in one area of the screen, ordered and sorted by 'track number'. How you get to a specific recording is usually handled in a different part of the screen which is ordered, grouped and sorted by the first three components of our primary key.
So, Composer+Genre+Extended Composition Name+Movement Number will work perfectly well in all known music players on all known conventional operating systems (proprietary hardware using restricted displays and unusual ways of accessing music have their own ways of doing things, so all bets are off for them!). Organising your recorded music in this way, therefore, provides a highly functional, flexible, scalable way of allowing you to access any particular piece of music in seconds.
The reason it does so is because it's based on a good data model: working out what minimum pieces of data are required to get to a specific recording of a work, taking into account the practical issues of having to work with a media player that does things certain ways, and also keeping in mind the practical difficulties associated with wading through huge numbers of compositions that certain composers wrote in their busy lifetimes.
9.0 But what about all my other data?!
At this point, there's a certain inevitable concern that creeps into some people's minds: if you've reduced my music library down to just four pieces of unique data, how do I find music in the key of E flat? Or how do I find all the recordings of Galina Vishnevskaya? Or, how do I see and work with <list some obscure piece of recording-iana here>?
The answer is fairly simple: The four pieces of information I've mentioned are merely the key to accessing all the other information you might want to record about a piece of music. They aren't the total information you record about a recording, merely the key pieces necessary to find "this" recording as distinct from "that" one.
By way of analogy: the row number and column letters in your spreadsheet aren't the data you're really interested in. It's simply the piece of data you use to quickly find and locate the data you're actually interested in. "Where are the sales figures for the Consultancy division for 2018?" is the question: "Row 67, column G" comes back as the answer. 67G isn't, then, a piece of information of value in its own right, but merely the 'address' where you can find the information which is valuable.
The same is true in this scheme of finding recordings of music. "Beethoven, Symphonic, Symphony No. 5 (Karajan 1962)" is merely the key to finding the four tracks or movements that make up that recording. That the piece was played by the Berlin Philharmonic is not an unimportant piece of information, but it's not the way you organise your music library. It's a piece of data that you fetch whenever you supply the 'primary key' data elements. Which is to say, click through composer, genre and extended composition name, your music player will display the tracks that belong to that specific recording -and each track will have additional data which can be inspected (or searched for).
The other data you might want to store about a piece of music is generally quite highly unstructured text. That it's in C minor; that the recording engineer was John Culshaw; that it was recorded on a Saturday morning after a big night out the previous Friday: all of this stuff can be recorded if you want it to be. Generally, however, I would personally only really want to store the full details of the performance or performers for any recording: remember, at this point, we've only got the surname of one 'distinguishing artist' recorded as part of the composition name. How about mentioning that the Oslo Philharmonic is playing, that Ben Titmarsh is playing the flute, and that Jeremy Twiddlethorpe is singing the solo treble part, for starters?
The key thing to understand at this point, however, is that this sort of information isn't as "significant" to a music player as the four pieces of information we've declared to be the 'primary key' of recorded music. The composer, genre extended composition name and track number data items are crucial to finding the music in the first place, so they are necessarily highly structured and standardised data items. By this I mean you don't want to type the composer's name as "Beethoven" for one recording and "Beethoven, Ludwig" for another -because now you have two data items describing the one composer, and that means you'll have two things determining a sort/grouping order. Functionally, it means your music player will list Beethoven's music in two completely different places, which destroys the concepts of discoverability and functionality we're aiming for.
So, those 4 primary key data items need to be entered and stored in a highly consistent manner (though you get to decide on what that consistently-used format should be, of course).
But everything else is pretty much just free-form text, with no requirement for rigid rules and consistency. Want to call it the "BPO" for one recording and "Berlin Philharmonic" for another and "Berlin Philharmonic Orchestra" for a third: be my guest, in the sense that no-one will stop you doing it and no fundamental music-discovery process will be harmed by you doing it.
Except... if you're the kind of person who ever approaches their music collection and idly wonders, "I wonder if I've got a recording that involved Herbert von Winkleman playing flute with the Berlin Philharmonic, you're going to get into trouble if you have been inconsistent with how you entered data about which orchestra was playing. It's easy to do a search in most music players for "Berlin Philharmonic", for example. But if you've entered the crucial data as "BPO" on the one recording you've got of Winkleman playing flute, you're search isn't going to find it!
For this reason, whilst it's not a strict requirement to type in non-key data in a highly structured, organised and consistent fashion, practically it makes sense to try to do so.
For myself, I only ever record four things about a recording that aren't in the already-mentioned primary key: Full conductor's name; Orchestra's name; Choir's name; Soloists name and roles.
Obviously, not every recording will feature a Choir; chamber works will not feature a conductor, choir or orchestra! So I might not type in every one of these four items for every recording, but when I do, they'll be in that order and I'll try to be consistent about it: if it's 'Wien Philharmonie' on recording, it won't be 'Vienna Philharmonic Orchestra' on another, for example.
And where do I type these extra pieces of lightly-structured free-form text? There aren't many places offered by most tagging software where large amounts of free text can be typed comfortably. Take this screenshot, for example:
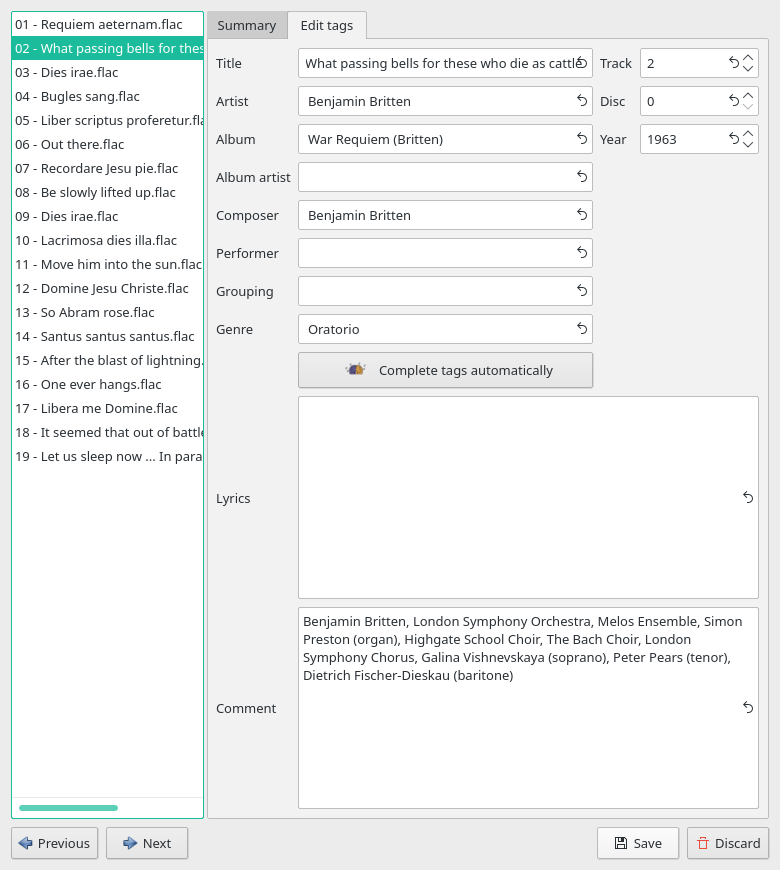
That list of performers you see at the bottom of the screen is quite long (234 characters long to be precise). It could have been typed into any of the displayed fields (apart from the four associated with the primary key, of course!). I've chosen to stick it in the COMMENT field. Why not use the LYRICS area, which is just as big? Because most music players will display comments (though some will have to be configured to do so). Many will not display lyrics. It's as simple as that, really.
Why not stick it in the PERFORMER field, which seems ideally named for it? Three reasons, really.
First, it is displayed in this particular software as quite a narrow field. That doesn't mean PERFORMER can't store 234 characters or more of data: there's no practical limit on what any of these fields can store these days. But if only a small part of it is displayed at a time, it will be difficult to type it in or read it back.
Second, a lot of music players will display and search COMMENT tags: it's a 'standard' tag that most media players expect to find. LYRICS and PERFORMER are not quite so standard, and a lot of media players simply won't know they're there in the first place.
And third (and possibly the most important): it really doesn't matter what your tags are called. Every single tag in a FLAC file is simply a key-name=value pair. None have a formal data type associated with them. I mean, for example, that though there's a tag called "DATE", if you choose to type the word 'violin' in there, no-one will stop you doing so. There is no external validator looking at what you put into your tags saying 'that's not the sort of data you should be entering there!'. So, you type in the data that's important to you in whatever field (i.e., tag) that your favoured music-playing software presents and uses in the most effective manner, keeping in mind as you do so that what your favoured music-playing software is today might be different tomorrow!
This last point is important too. Clearly, Clementine likes to display COMMENTs in large areas of text. It's my daily driver as a media player. So I'm happy... for now. The real question to ask yourself, however, is do other media players and software work similarly. If they do, then Clementine isn't just being unique and peculiar, so playing to its particular strengths today won't screw you over if you ever switch software in the future. So, is Clementine unique in the way it handles the COMMENT field? Well, here's dbPoweramp on Windows:
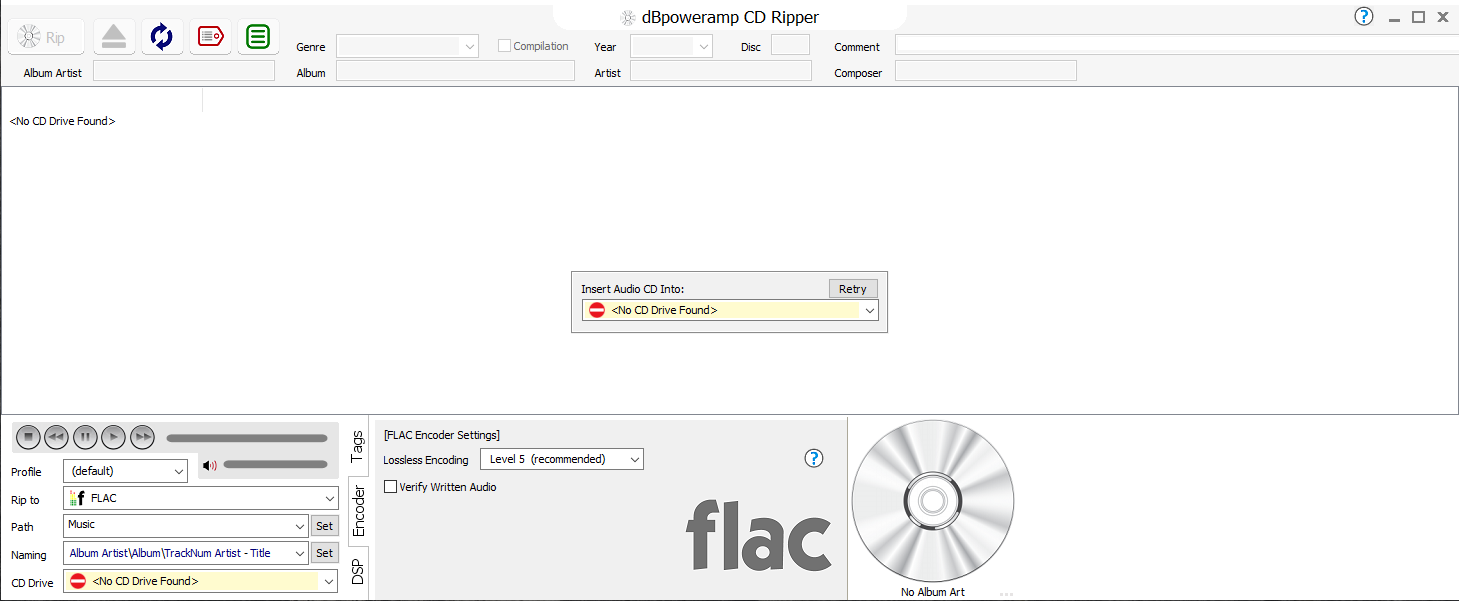
Notice how long the 'Comment' field is at the top right-hand corner of the program display area? In fact, it appears to have no end, just running directly into the right-hand edge of the program display area without a pause. Practically, it really does accept any huge amount of text you type into it. But notice that all the other data fields are formally limited in size: they will certainly accept long data entry, but its display will be truncated, making viewing it all (and thus inspecting it and editing it into shape) problematic.
Here's another example, using a piece of software called TagScanner:
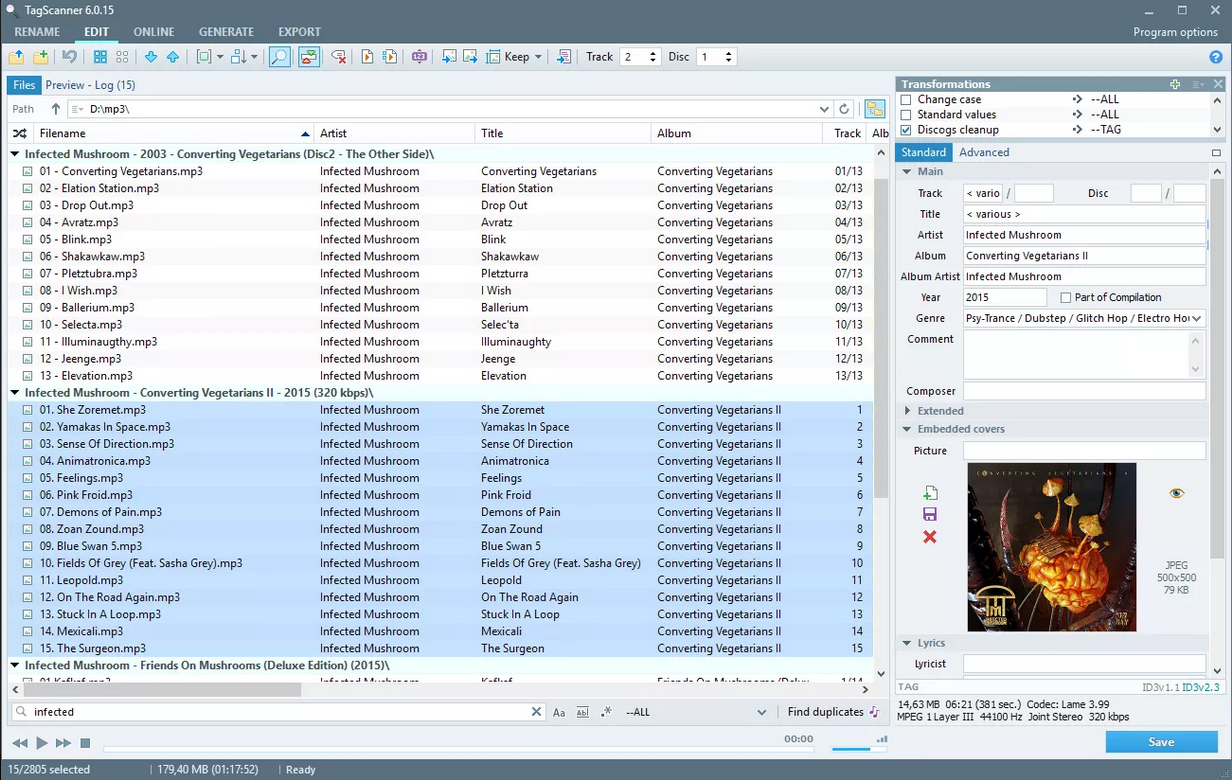
Again, spot that large area for free-form comments over on the right-hand side of the screen; spot the very-tightly constrained sizes for all other tag fields, too. So a pattern emerges that a lot of audio-related software expects COMMENT to be long and full of data that needs to be displayed in large, long fields, not short, little ones.
On the other hand, it doesn't always work that way, of course. Here's MP3Tag, a very popular tag editor on Windows:

Note that in this software, the COMMENT field is strictly size-constrained like all the others -and in consequence, the display is severely limited and clearly runs off to the right of whatever the program manages to display. Again, this doesn't mean the program can't actually store long data in that field; it merely can't display all of it at once.
So the point is that software is varied and does different things in different contexts. So it's possible that telling you to store a lot of data in COMMENT might not be right for you and your particular choice of software -but it's the only tag that a lot of software displays in large format and it's one of the 'standard' tags that nearly all software can display and search in, without lots of re-configuration effort required. So my recommendation stands!
Accordingly, my four non-key pieces of data about a recording are always entered into the COMMENT field for each music file. I naturally suggest you do likewise -but feel free to add other bits of data into it, too, that you find useful to know about a recording.
Once that sort of non-key data is stored in the COMMENT field, most music players will let you display it if you want to -or at least search through it and filter by it if you need to. Once you've recorded "John Thistlethwaite (oboe)" in a COMMENT tag for a recording, you'll be able to search your entire music collection at any point for any recordings on which Mr. Thistlethwaite ever played.
10. A final thought about non-key data
Some people have really very precise requirements of how to find music in their collections. For them, I think the fairly casual COMMENT approach I've described above in Section 9 may not be sufficient. Accordingly, I'd suggest a more structured way still of doing things for such people.
For example:
Conductor: Neville Marriner
Orchestra: Academy of St. Martin-in-the-Fields
Choir:
Soloist: Nigel Kennedy
Solo Instrument: Violin
Key: B minor
Catalogue ID: 61
Recording Engineer: Fred Dimples
You could construct a simple text-file template that prompts for all the unique pieces of data you fancy storing about a recording: a simple copy-and-paste then gets the prompts into the COMMENT field and you simply fill in the appropriate gaps as required. Fundamentally, storing the data in this way achieves not much more functionally than typing it in as:
Neville Marriner,Academy of St. Martin-in-the-Fields, Nigel Kennedy (violin), B minor, Op. 61, Fred Dimples
...but to those that care deeply about the minutiae of such data, presenting it nicely and making it intelligible at a quick glance is probably a desirable goal.
There is a third alternative approach, though -at least if you use FLACs as your audio format of choice. There is nothing to stop you storing any "key=value" pair within a FLAC file. For example, at a command prompt, you could type a variant of this sort of thing:
metaflac "--set-tag=RECORDINGENGINEER=Fred Dimples" "01-Inaffia l'ugola.flac"
That's creating a brand new tag called 'RECORDINGENGINEER within a specific audio file and setting it to have a value of 'Fred Dimples'. Everything you type into the COMMENT tag, in other words, could be stored in what are known as "Custom Tags", in a highly defined and structured fashion. Unfortunately, you likely won't find a GUI program that easily adds such custom tags, but the command line is not too bad an option if you're used to it.
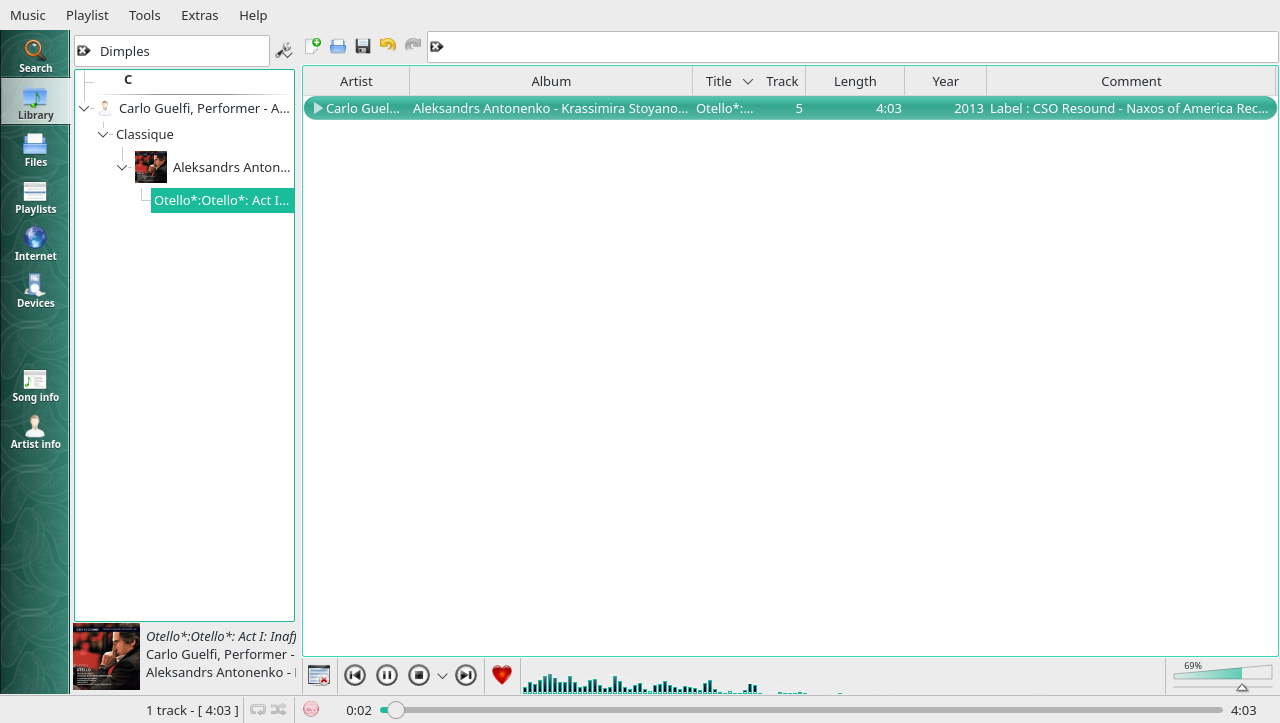
Given that it's relatively easy to do, why don't I recommend you do it this way, then? Simply because hardly any software in existence will let you see or interact (or, potentially, search) by data you store in a custom tag. The data is there, then; but it's usually quite inaccessible (and therefore of no practical use). Here, for example, is me trying to find the one track I've said Fred Dimples worked on in Clementine:
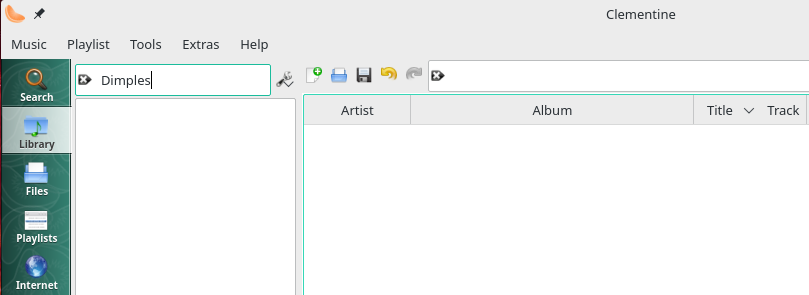
The search term is typed into the search window... but no music is found containing that tag. In fact, if you use Clementine's own tag editor, you won't even know the new RECORDINGENGINEER tag exists in the file at all:
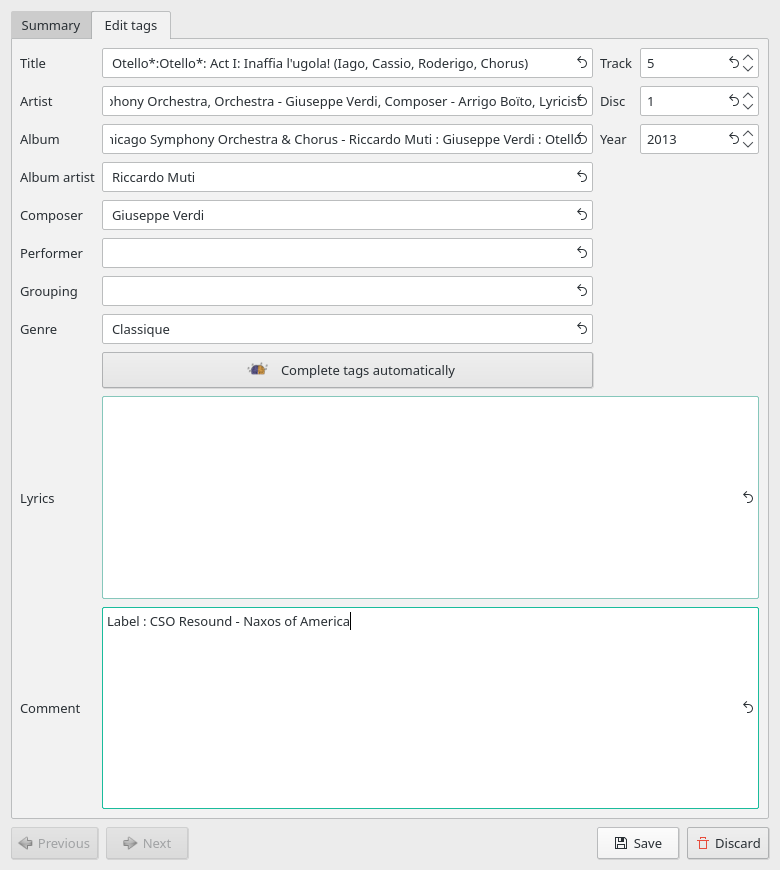
No sight of Fred Dimples there, I fear! So, custom tags are like that: wonderful in theory, pretty useless in practice, unless you have very re-configurable music player software and are prepared to put in the time and effort needed to customise its search capabilities, anyway.
Meanwhile, if I stick to the approach of putting all my important information inside a free-form text tag which all media players know how to display and query when asked, much better results can be achieved without major effort. For example:
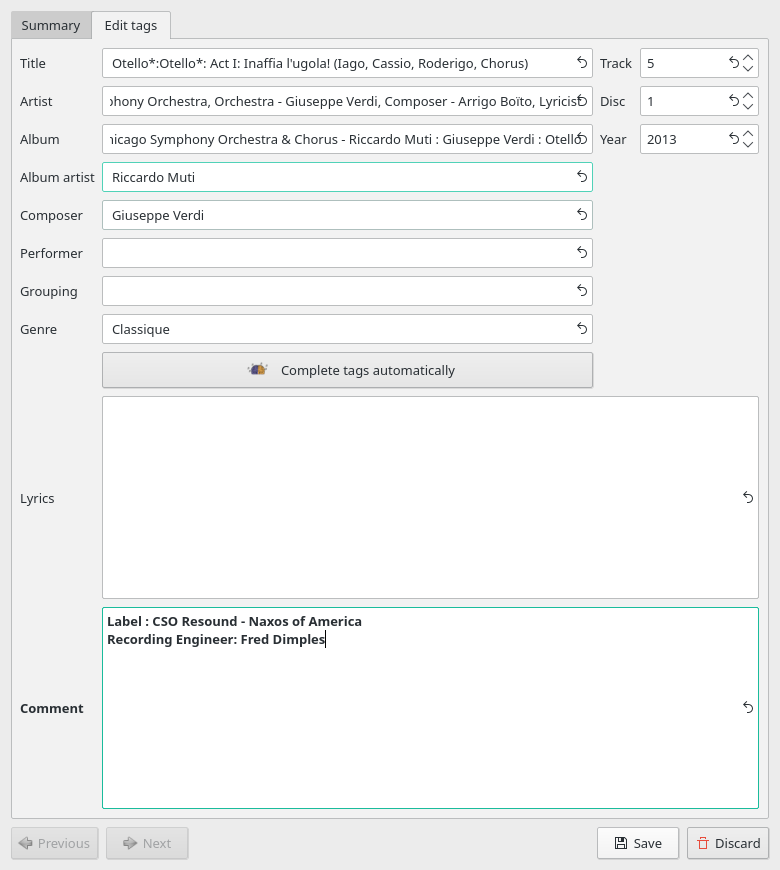
Here, I've just added 'Recording Engineer: Fred Dimples' to the COMMENT tag. Save that, and try my earlier search again:
Bingo: the search term is there as before.. and now something that matches *is* being displayed in the left-hand navigation pane, so it's a simple click to make it play in the right playlist pane. If the data is in the COMMENT tag, most media players can find it and use it (including iTunes!).
Some people are offended by the idea of putting a lot of diverse data into a single tag field like this, but they really shouldn't be! A tag takes whatever information you care to throw at it: it's simply a key/value pairing and has no intrinsic meaning apart from what meaning you choose to invest in it. So long as the data you supply is searchable and can be used as the basis of filtering your music library, it's a highly functional approach to take.
11. Universality
Do these music tagging suggestions apply universally? They surely do, though that doesn't mean they will necessarily and always apply to your very special and particular way of interacting with your music collection! People are unique, of course, and so it's entirely possible you interact with music in a unique way that this proposed organisation scheme cannot possibly accomodate.
Whenever I've been dealing with people who say, 'Oh, your scheme won't work for the way I listen to music', however, almost without fail, it will turn out that they are using a specific piece of audio hardware; or that they don't actually know fully how their music software works and have thus accommodated themselves to its 'failings' without understanding that those 'failings' are trivially worked around. On at least two occasions, I've been told 'your scheme won't work for me', only to find out that on both occasions, it's because the individuals concerned can't actually be bothered to tag up their music at all. For sure, if you can't be worked up enough to tag your music files properly, then no organising scheme on Earth can help you out of the hole you've dug for yourself!
But, assuming you are using standard desktop computers or mobile phones; assuming that you care enough about your music to want to organise it efficiently and effectively in the first place; and assuming you are therefore prepared to put in a little effort in assigning appropriate metadata tags to your digital music files... then, yes: the scheme I've just outlined above will and does apply universally.
By that, I mean, these ideas will work for every music player I know about, on every operating system I've ever used, and one's access to your music will remain fast, efficient and effective on all of them. The fundamental reason for that is simply this: the data model is sound: correctly and technically identifying key-data and distinguishing it from non-key data is the crucial ingredient here. If the data model is sound, it will be portable across players, devices and operating system environments, without drama.
Remember that all music players display music in a default way: the use of a 'primary' key as I've suggested here will ensure that your music is always sorted in composer/genre/extended composition name order, which is the natural way to identify any one recording distinct from any other. Most music players of my acquaintance will default to this sort of sorting/grouping order out-of-the-box, or with a very little bit of re-configuration. Hence, what information theory says is the most efficient way to retrieve a specific recording turns out to be the 'natural' way most music players are configured to organise things, too. (Coincidence? Not, I would say!!)
Remember, too, that if you expect to be able to find music by ways that aren't the "natural" way, that's entirely fine too. A proposal to order data one way shouldn't interfere with your rights and ability to access data in other ways. The fact that you can only order data in one way, but that there are an infinite number of different ways to access data, inherently and implicitly means your music playing software must offer the ability to search comprehensively through all your tags, rather than just stick to displaying information sorted by a handful of them. Fortunately, the bar is quite a low one to clear: provided your music player allows searching the COMMENT tag, and also provided that your non-key data is stored coherently there, then you'll always be able to use the media player's search functionality to filter your music collection by it.
Of course: if you're using some obscure audio playing/management software on a hardware platform I've never used to achieve something other than fast access to a specific recording, these proposals may well not apply to you. That makes you the 1% exception that otherwise proves the rule, I'm afraid. I wish I could meet your exacting and unique standards, but if the above doesn't do it for you, then you really are on your own. (Which is a polite way of saying, if you insist on fighting basic information theory, I can't help you!)
12.0 Conclusion
For some reason that I have yet to understand, the topic of how best to tag classical music tends to engender a lot of heat and anger rather than light! I think it's because what I've documented here seems to be telling people "you've been doing it wrong all these years!" and they get somewhat defensive as a result.
And, to be fair: I probably am saying they've been 'doing it wrong' to some extent. In my professional data management opinion, the tagging/sorting/ordering scheme I've outlined here is the only natural one available -and it happens to be extremely efficient and scalable, too -because it seeks to specify the minimum data elements required to achieve a unique 'hit' on a specific recording of a specific composition. It's because it's soundly based on information theory principles that it works so well: but you needn't care about them, just the fact that your huge music library is easily navigable and highly discoverable.
In short: I commend the Composer/Genre/Extended Album Name + extensive use of the COMMENT tag to you, anyway... and look forward to hearing from you if it fails your specific needs.
In a second article, I examine in much more detail the sorts of things that affect what you put into the various FLAC metadata tags that are available to you in more detail, but I think this article has outlined the general principles enough to be going on with 🙂