 When I buy digital music from the likes of Prestoclassical, it often (though not always) comes with a digital PDF version of the booklet that would have accompanied the physical CD in its jewel case. An example of the front page of one such PDF is shown at the left, belonging to a digital download of the film music of William Alwyn I bought back in October.
When I buy digital music from the likes of Prestoclassical, it often (though not always) comes with a digital PDF version of the booklet that would have accompanied the physical CD in its jewel case. An example of the front page of one such PDF is shown at the left, belonging to a digital download of the film music of William Alwyn I bought back in October.
The trouble with such digitised booklets, however, is that the PDF often contains data embedded within the file that is not necessarily something you want to keep. In this case, for example, if I open the purchased booklet PDF in my standard PDF viewer (on Kubuntu, that's Okular) and select File -> Properties, I see this:
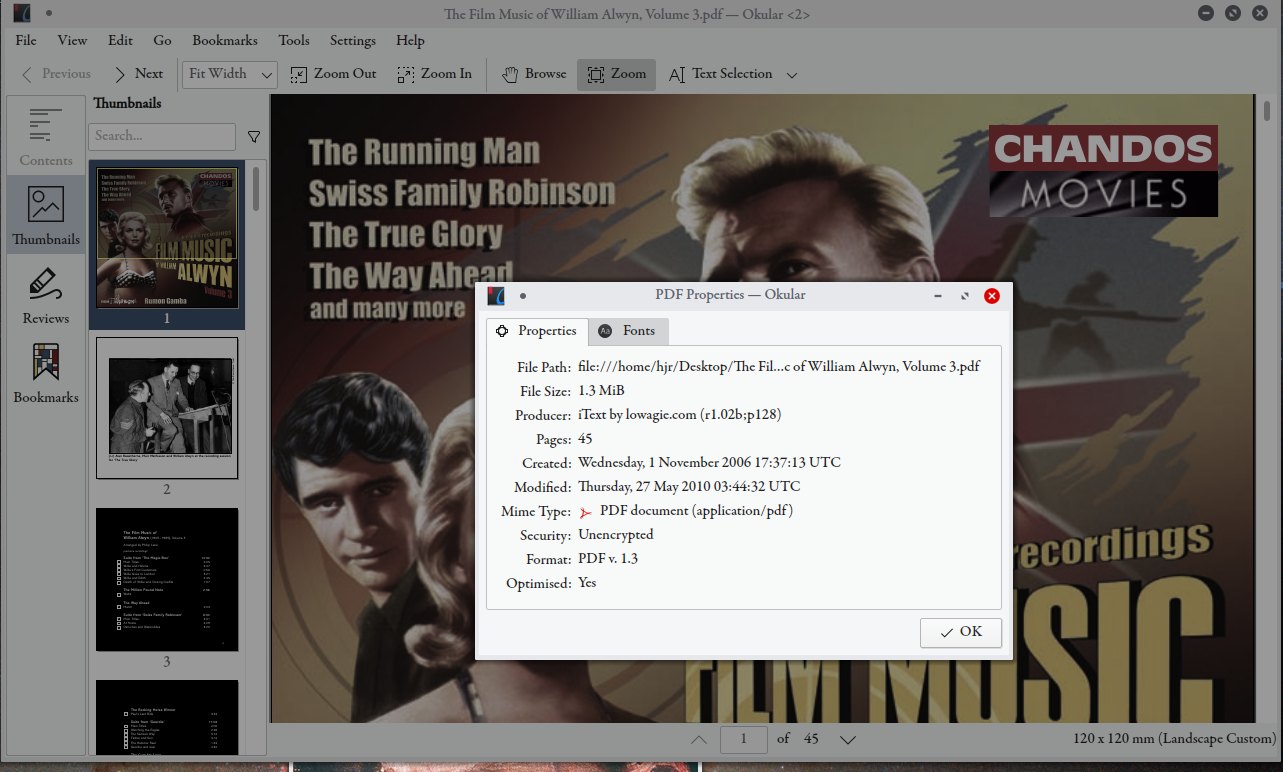
Most of the stuff displayed in that properties dialog box is fine and perfectly normal, and wouldn't concern anyone... but what's that 'Producer' data? It's saying it's been produced by 'iText by lowagie.com...', but I haven't the faintest idea who they are, what tool they're using, or why they are entitled to a mention in my PDF metadata!
The short version of this blog post, therefore, is: how do I strip this sort of nonsense metadata out of my PDFs, so that my files are not silently tagged with data I don't want them to be tagged with?
Well, to fix this, you'll need two programs installed on your Linux box: exiftool and qpdf. You may find both tools already present in your distro, but on Kubuntu I had to install both with the command:
sudo apt install exiftool qpdf
The metadata stripping process then basically begins with the command:
exiftool -all= *.pdf
Note the strange spacing around some of that. It's hyphen-all-equal-space, then the name of whatever PDF you're trying to 'clean'. So here's a worked example:
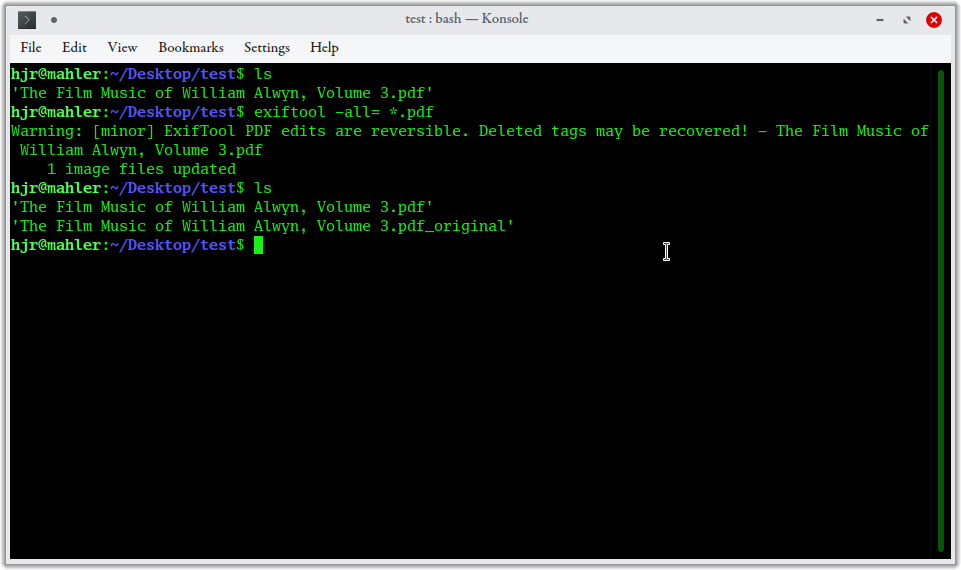
First, I cd to a test folder. There, I see that I own one PDF, with a name of 'The Film Music of William Alwayn, Volume 3.pdf'. I therefore type in the exiftool -all... command. A "minor" warning is produced (and I'll come back to this in a moment), but otherwise I'm able to list the contents of the folder once more -and, this time, I now have two PDFs: one called 'The Film Music of William Alwayn, Volume 3.pdf' and a new one called 'The Film Music of William Alwayn, Volume 3.pdf_original'.
This is a feature of the exiftool: it creates a new file, lacking metadata, with the same name as the original input file... but it also preserves the original file with a '_original' added to its file extension. It's trying hard not to be destructive, basically!
Crucially, however, here are the Okular file properties dialogue for the new, non-original, PDF:
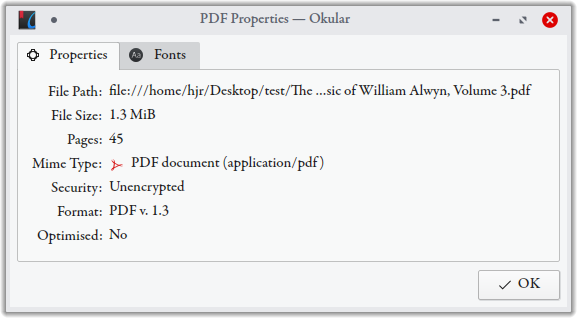
You will immediately notice the absence of anything referring to Producer, iText or lowagie.com. The command has, indeed, stripped the unwanted metadata from my PDF! Result!!
Except... back to that original warning message I received when I issued the exiftool command: Warning: [minor] ExifTool PDF edits are reversible. Deleted tags may be recovered! The message is being pretty explicit: though the metadata for Producer is apparently gone, it's actually still there, under the hood, and could be recovered if desired. (For the record, the command to reverse the metadata wipe in my case would be: exiftool -PDF-update:all= The\ Film\ Music\ of\ William\ Alwyn\,\ Volume\ 3.pdf).
To make the metadata removal permanent, the qpdf tool must be employed, using a variation on the command:
qpdf --linearize --replace-input input-file-name.pdf
The 'replace-input' switch basically means that qpdf over-writes the input file, so that the file name doesn't change at all, but the contents of the file will now be over-written by the 'linearized' output. That basically means the PDF cannot be returned to the metadata-full state it was previously in.
In my case, therefore, I'd have to type:
qpdf --linearize --replace-input The\ Film\ Music\ of\ William\ Alwyn\,\ Volume\ 3.pdf
...but because I'm getting a bit fed up with those long file names with spaces and punctuation characters that all need escaping, I'd follow that up with a mv -f *.pdf booklet-cleaned.pdf command so that the PDF we're now dealing with is called, simply, 'booklet-cleaned.pdf'. I can bolt that extra bit of processing onto the original command to produce a single command like this:
qpdf --linearize --replace-input The\ Film\ Music\ of\ William\ Alwyn\,\ Volume\ 3.pdf && mv *.pdf booklet-cleaned.pdf
It looks quite a messy command as a result, but the outcome is that my folder now contains two different PDFs:
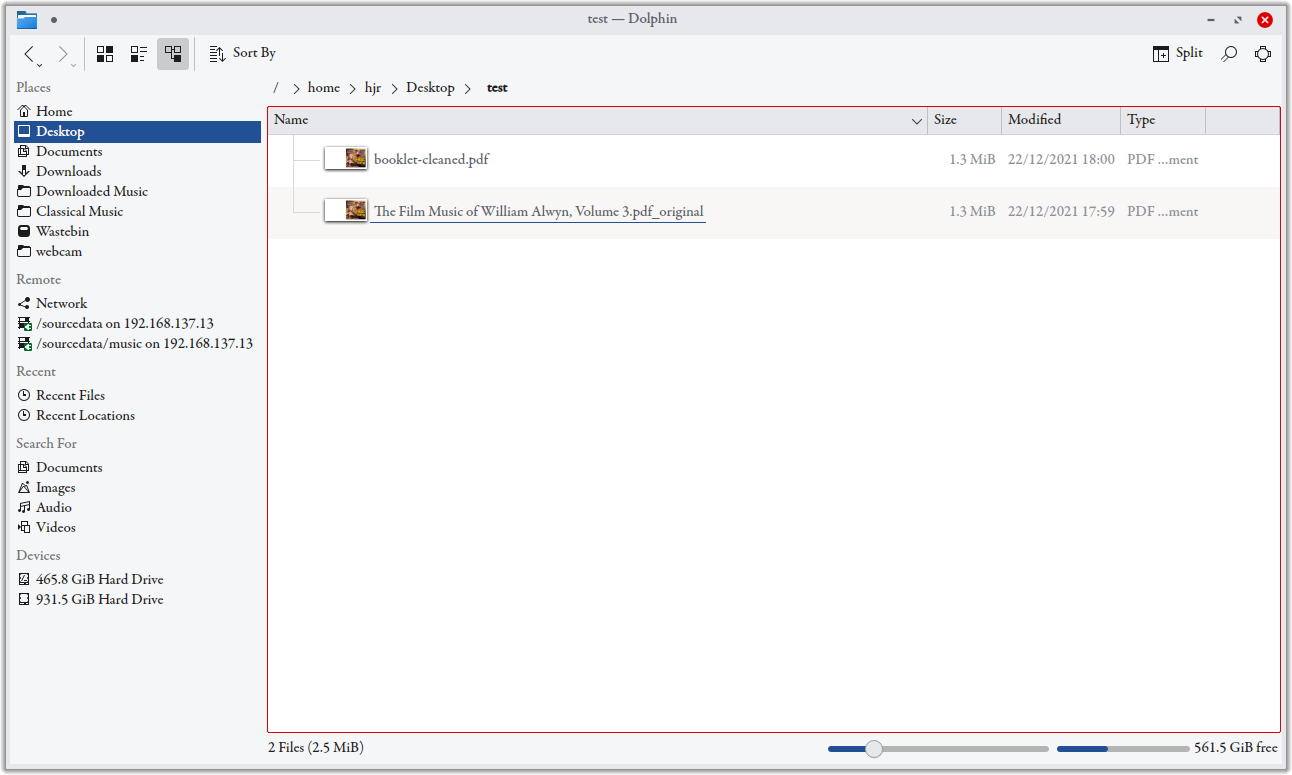
The one called ...pdf_original is, indeed, the original file, complete with unwanted metadata. The new 'booklet-cleaned.pdf' file is the output of the qpdf command: it's had its metadata irreversibly cleaned out and it's simultaneously been renamed to be 'booklet-cleaned.pdf', no matter the original file name that gave rise to it.
So, with two small bits of new software and a couple of commands in a terminal, it's possible to clean all your PDFs of unwanted and extraneous metadata fairly easily.
But, this being Linux, we can of course simplify the process even further! Here, for example, is a string of concatenated commands that will achieve the irreversible clean of metadata required, but without generating multiple intermediary files along the way:
exiftool -all= *.pdf && qpdf --linearize --replace-input *.pdf && mv *.pdf booklet-cleaned.pdf
The double-ampersands make the qpdf command run after the exiftool one completes. I've also used wildcards in the various input file names, so it doesn't matter what a PDF is called specifically: this combination of commands will always result in the correct processing of the relevant files, regardless of their names. Here, for example, is me processing a new PDF in the same test folder as I was previously using:

You can see that I start with a single PDF, as before. I then issue my wildcarded combo-command, and perform a final ls -l to list the folder contents: this time, I again see two PDFs listed: the original PDF and the irreversibly-cleaned version of it (which happens to now be called 'bookle-cleanedt.pdf').
All we really need at this point is some way to clear out all the PDF files which are not called 'booklet-cleaned.pdf' -as they are the original or intermediate files I'm not interested in retaining. Well, the simplest way I know of deleting files which aren't called something specific is to issue variations on this command:
find . -type f ! \( -name 'booklet-cleaned.pdf' -o -name '*.flac' -o -name '*.jpg' \) -delete
There are some naughty assumptions underlying this version of the command, which are going to be true for me... but might not be true for you, and could therefore wreak utter havoc! The command says 'find files whose names are not booklet-cleaned.pdf, or anything.flac, or anything.jpg. Everything you find matching those criteria, delete. No questions asked, and no possibility of a change of mind!
I structure things this way round because I know I will only ever run this 'clean my PDF' command in a folder of music in which Presto (or an equivalent digital music provider) has supplied a bunch of FLAC files, a booklet PDF of some name or other, and (probably) a JPG version of the album cover art. So I want to delete the intermediate PDFs, but I don't want to delete the FLACs or JPGs. Hence, I make specific exclusions for those types of files... but woe betide you if your music provider has included assorted .txt or .doc files, for those are not excluded from the delete, and so would disappear in an instant.
So, recognising in advance the danger of deleting files in bulk on the basis of 'not named like' tests, if I bolt that onto the previous combo command with a new set of double-ampersand characters, you get this:
exiftool -all= *.pdf && qpdf --linearize --replace-input *.pdf && mv -f *.pdf booklet-cleaned.pdf && find . -type f ! \( -name 'booklet-cleaned.pdf' -o -name '*.flac' -o -name '*.jpg' \) -delete
...and that will now do the entire convert, make irreversible and clean-up process in one hit, as you can see here:
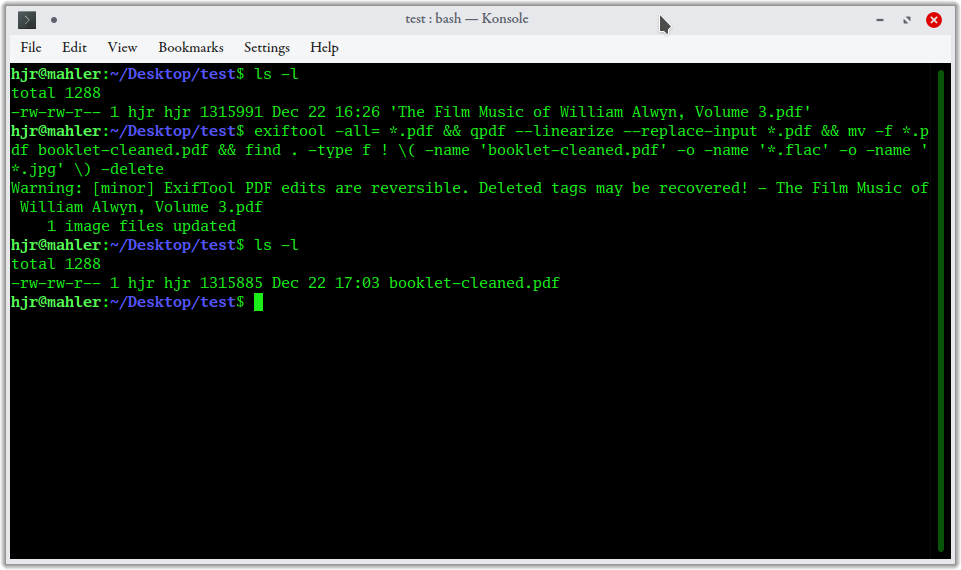
Again, I start by listing the contents of my testing folder: it contains a single PDF with an elaborate composer-and-composition-specific name. I then issue the new exiftool+qpdf+find combo command, which appears to 'do stuff'. And finally, I issue a last 'ls' command... and find only a single PDF listed, called booklet-cleaned.pdf. All the intermediary files have gone, leaving only the irreversibly-cleaned PDF, with its standardised file name.
The only thing we really need to do at this point is tack on yet another command to the existing combo command to result in a rename of the 'booklet-cleaned.pdf' to a plain, simpler 'booklet.pdf'. This will do the trick:
exiftool -all= *.pdf && qpdf --linearize --replace-input *.pdf && mv -f *.pdf booklet-cleaned.pdf && find . -type f ! \( -name 'booklet-cleaned.pdf' -o -name '*.flac' -o -name '*.jpg' \) -delete && mv booklet-cleaned.pdf booklet.pdf
And that will do the trick: a single existing PDF will be permanently cleaned of extraneous metadata and then renamed to be 'booklet.pdf', without any surrounding FLACs or JPGs being damaged or modified or deleted in the process. Job done!
I now do just one final thing: I wrap that entire 'combo' command up into a single alias and stick it into my .bashrc file, so that I can invoke the long sequence of commands with a simple, short name. Here's my .bashrc entry for it, for example:
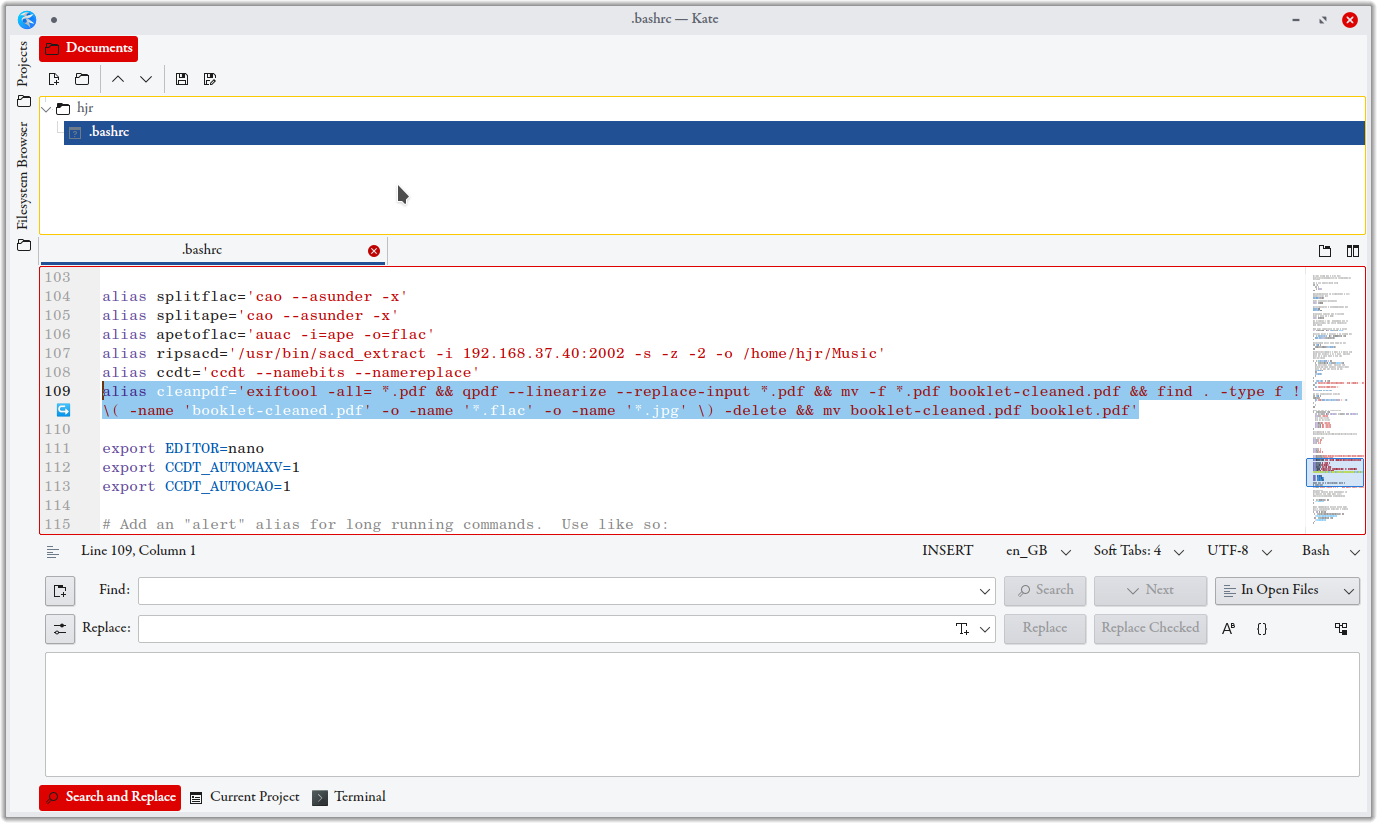
I've highlighted the relevant line. By saying alias cleanpdf='....<combo commands>....', I've created a new, simply-named command called 'cleanpdf' which, when issued, will actually perform all the commands that are listed after the equals sign. Once that edit's in-place, and once I've opened a new terminal session so that the new alias is picked up and applied, I can now do this:
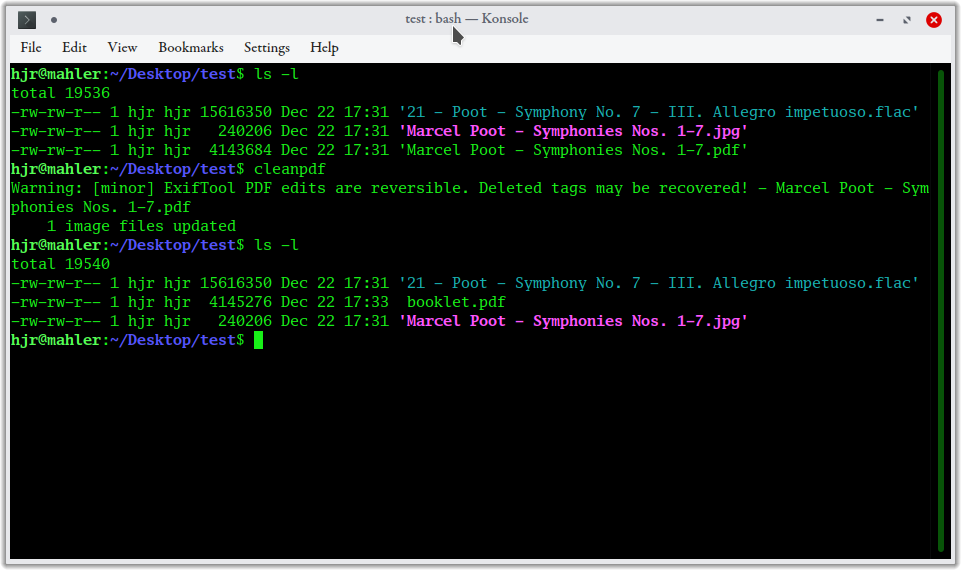
That is:
- I once more start by listing the contents of my test folder and discover one, complicatedly-named PDF, plus a FLAC and a JPG.
- I then issue the simple command cleanpdf.
- A second, new file listing reveals the existence of a new booklet.pdf, which is the irreversibly-cleaned version of the earlier-listed PDF. The FLAC and the JPG are still there, too, however.
So now I have a one-word command that will do a lot of file converting, cleaning, and deleting... all of which results in the production of one, standardly-named PDF that is irreversibly clean of any unwanted metadata. Nice!
I should point out, of course, that the alias is assuming quite a lot of things in order to work. The principle assumption is: there's only one PDF to process in any given folder! If there's more than one PDF in a folder, the string of commands will break quite nastily. One could prevent that by pre-prending a count of files to the main alias command and only proceeding if the count is one. For example, if we change the aliased command to this:
[ $(ls *.pdf | wc -l) -eq 1 ] && exiftool -all= *.pdf && qpdf --linearize --replace-input *.pdf && mv -f *.pdf booklet-cleaned.pdf && find . -type f ! \( -name 'booklet-cleaned.pdf' -o -name '*.flac' -o -name '*.jpg' \) -delete && mv booklet-cleaned.pdf booklet.pdf
...then the first bit within the square brackets means 'only do the exiftool, qpdf and find commands if the count of PDF files in this folder is exactly 1': we're taking advantage of the fact that in Bash and similar shells, concatenated commands only proceed if the prior command completes successfully. Since the square bracketed bit is saying 'the count of PDFs must be 1', if that part fails, the double-ampersanded following commands cannot be executed. Unfortunately, of course, this means that if processing fails, you won't know about it: the command will simply not clean the PDFs present, but will fail entirely silently.
Well, that can be fixed too:
[ $(ls *.pdf | wc -l) -eq 1 ] && exiftool -all= *.pdf && qpdf --linearize --replace-input *.pdf && mv -f *.pdf booklet-cleaned.pdf && find . -type f ! \( -name 'booklet-cleaned.pdf' -o -name '*.flac' -o -name '*.jpg' \) -delete && mv booklet-cleaned.pdf booklet.pdf || echo "Fail! Too many PDFs in this folder!"
Now the use of a double-pipe at the end of the command (which is the shell equivalent of 'or') means, if the PDF count is 1, then do all the cleaning, or echo a message indicating failure for... reasons!
And so on. There are probably lots of other assumptions being made which could similarly be tackled, piecemeal. I know some readers wouldn't want all their final output PDFs to be called 'booklet.pdf', for example. But I'm basically writing for me, and I'm reasonably confident that whatever other hidden assumptions there may be behind this sequence of commands, they can be lived with. Your mileage will, of course, vary.
I think the serious point here, however, is to take ownership of your PDFs as you do your FLACs. Digital music purveyors will supply you with PDFs that contain all manner of hidden metadata that you neither asked for nor require. By a little bit of coding and aliasing, you can give yourself the power to clean your PDFs of all this fluff as you choose.