1.0 Introduction
If you have ripped your CDs to FLAC file format, I can be fairly certain that you care about your music and want to ensure you are listening to the complete audio signal as originally supplied on CD. I can therefore be fairly confident in assuming that you would want to make sure your FLAC music files don't get corrupted over time, in ways which may make them unplayable at worst, just inaudibly different at best -and perhaps audibly different as the most common possibility. This article explains how you can tell whether a FLAC file has the same internal contents as it had the day it was created -or, alternatively, how you can detect that the contents of the file have changed over time, necessitating either a fresh rip from CD or a restore from a known-good backup.
2.0 Native FLAC Testing
The people who invented the FLAC file format have provided a 'built-in' way of checking that a FLAC file's contents are 'good' or contain errors. If you've got FLAC installed on your system, you can simply run this command:
flac -t <name of file>
So, for example, here's me checking one of the movements from a Shostakovich symphony:
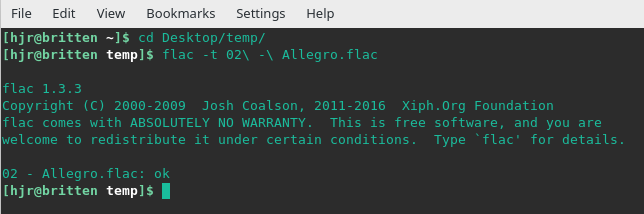
You can see I first navigate to the folder containing the file to be checked, then invoke the flac executable with the '-t' (for "testing") flag. The program reads through the file and declares at the end "ok"... so I know that the internals of this file are considered 'good'. The output is quite concise and the contents of the file are not modified in any way by the testing process: it's a completely non-invasive test. This means, for example, that the file's created or modified timestamps are not altered by running the test: the file looks exactly the same after it's been tested as it did beforehand.
Now let me introduce some corruption into the file (by opening it in a text editor, modifying one character and saving it). This time, I might see this sort of thing:
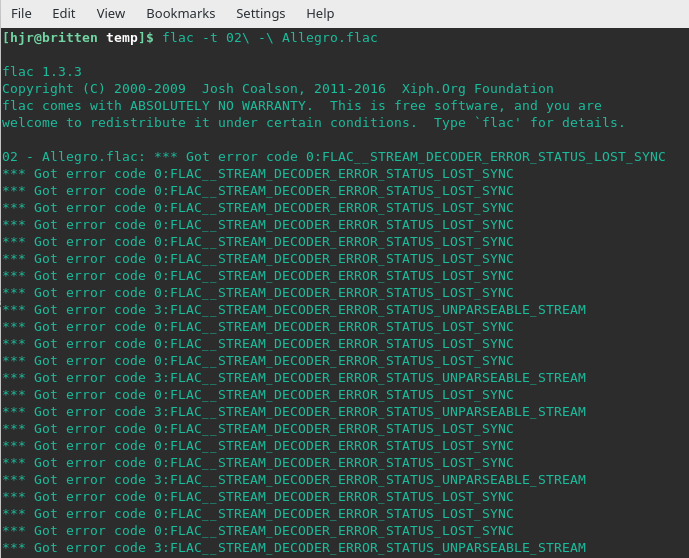
As you can see, the output is 'noisy', but it's pretty obvious something nasty has befallen this particular FLAC file! (Incidentally, trying to play this modified file in VLC, which usually plays pretty much anything you can throw at it, resulted in no playback at all... so the file is really broken!)
So, this -t testing is effective at spotting errors. But it's quite noisy in terms of outputting things and it's an all or nothing affair: either you test the file or you don't. There's no way to say, for example, 'please test this file if it was tested more than a month ago, but don't test it if not'. You can't even write a script to do that because the timestamps on the file aren't altered in any way by running flac -t against it, so the file will always appear to be dated when it was first created, not when it was last checked.
This is a bit of a problem for large music collections, because the native FLAC test actually reads and checks the file -so it consumes CPU and memory. It's doing 'real work' -and if you were to run it, say, once a month, you'd have to do that real work for every single file in your large collection of FLACs. For a collection around 50,000 tracks in size, that's likely to take over a day to perform, with your CPU pretty much flat-lined for the entire time. Do you fancy tying up your PC for that long, once a month? I certainly wouldn't welcome it! So let's see what other testing strategies might be useful that lend themselves to greater flexibility about what to check and when to check it.
3.0 MD5 Hashes
For any file, of any type, it's possible to compute what's called an MD5 hash for it. This is simply a long string, containing numbers and letters, which represents a mathematical 'summation' of the contents of a file. Change the contents of a file by a very tiny amount and the mathematics involved will generate a wildly different MD5 hash value when recomputed. Take this simple example:
echo "This is a text file" > test.txt md5sum test.txt d03fd97600532ef84ddc1e578ea843e9 test.txt
That's me creating a test.txt text file on my hard disk, containing the words 'This is a text file'. I then run the md5sum program against that file and obtain a long string (starting 'd03fd976...'), which is the MD5 hash for that file.
Now let me create a new file with very, very slightly different contents:
echo "This is a text file." > test2.txt md5sum test2.txt b264e4c43787cb81e7d4c5eb4b006427 test2.txt
In case you didn't spot the difference: test2.txt contains a full-stop which test.txt lacks. It's only one character different, but the MD5 hash value produced by the second file is vastly different from that created by the first. Now let me finish things off with a bit of a quiz:
md5sum test3.txt d03fd97600532ef84ddc1e578ea843e9 test3.txt
Here an MD5 hash is being computed for a brand new file, called test3.txt. You don't know what the contents of that file are, because I haven't shown you how I created it. But you can see its MD5 hash value. Can you therefore guess what the contents of the test3.txt file might be?!
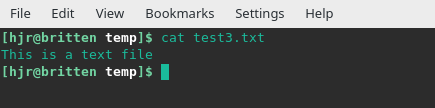
Since the hash value is identical for that of file test.txt, you can be fairly confident that the contents of the new file must also match those of test.txt... and therefore, test3.txt really does contain the identical text to that of test.txt, including the lack of a full-stop.
I will just mention at this point that MD5 has long been known to be cryptographically very insecure: on even low-powered PCs, it takes mere seconds to invent a string of words that would produce the same MD5 hash value as 'This is a text file', but that new string would not actually match the original. When two different things produce the same MD5 hash, we call that a 'hash collision' and if it's easy to deliberately create hash collisions then you must not rely on MD5 as a way of storing hidden versions of people's passwords (for example). So using MD5 for any sort of security function is a very, very stupid thing to do in 2020... but it's still good enough a way of 'fingerprinting' the contents of files. MD5 hashes can be thought of as 'fingerprints' for the content of files -and if that's the only way you're using MD5, you're still safe!
4.0 MD5 and FLAC files
So back to our original conundrum: how can you check that a FLAC file's contents are no different today than the way they were on the day the FLAC file was first created? Well, maybe we could create an MD5 of the file when creating it. Then some time later, we could re-compute the MD5. If the two hashes match, then the contents of the file cannot have changed in between times.
It's certainly possible to do this. Here's me and my Shostakovich Allegro once more:
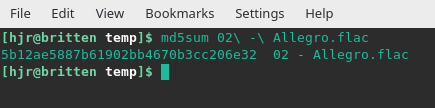
So, it's as easy to create an MD5 hash value for a FLAC file as it was for a text file. The problem is, a FLAC file's contents are a lot more complex than a simple text file -and some bits of it are things you definitely might want to be able to change without that meaning 'the file is internally corrupt'. For example:
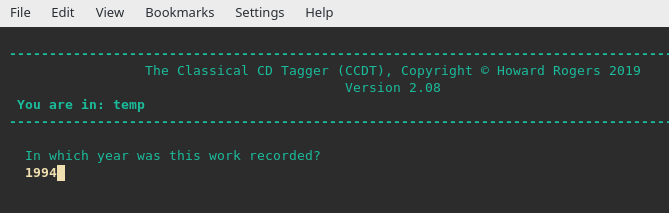
That's me launching the Classical CD Tagger to modify the recording year of the Adagio track: I originally had ripped the CD saying it was recorded in 1995, but now I've discovered I was wrong, so I'm putting that right. Once I've done so, let me re-compute the MD5 hash for the file:

Ooops. I only changed one tiny piece of tag information for that file, and its MD5 has changed from '5b12...' to '43d46...'. If you were relying on MD5 to tell you the file has changed in some way, then it's done it's job: the different hashes tell you the file has indeed changed. But this was a "legitimate" change. We really need a way of spotting corruption or bit-rot or some other form of illegitimate internal change -and, clearly, just taking an MD5 of the entire file isn't good enough for that purpose.
What we need, instead, is a way of computing an MD5 of just the audio within a FLAC file, ignoring any tag data which might legitimately be modified from time to time. It's only corruption of the actual music component of the file that is something we want to detect and spot when it changes. Can we do that?
Well, funnily enough, the FLAC developers have already thought of this and embedded an MD5 hash of just the audio component of the file at the time it was first created. It's already there in the file: you just have to read it to see it:

So now here's a third MD5 for this same audio file -but it's one that's already buried within the file, put there when it was first ripped from the source CD. All you have to do is use the metaflac --show-md5sum program to display it. Having thus seen the hash of the audio signal only is 'fe7baa18...', let me re-tag this file once more and check if modifying the tags in this file affects that MD5 hash value:
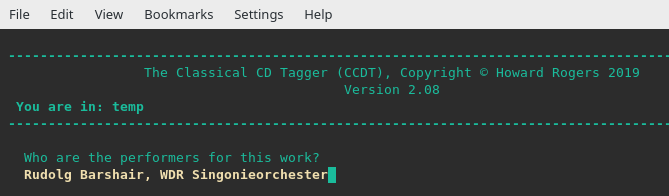
So this time, I'm adding details of the conductor and orchestra performing the work. That's quite a lot of new textual data being added into the FLAC. But:
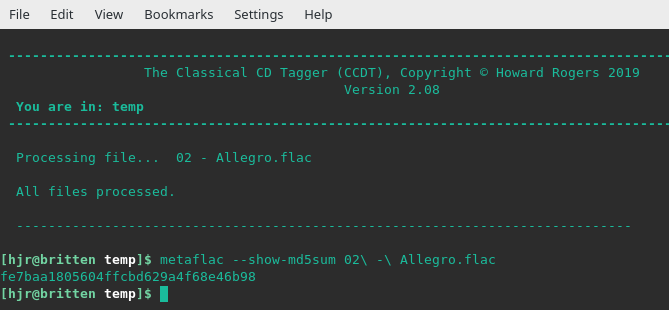
...we see that immediately after writing that new performer data to the file, the MD5 hash of the audio signal remains at 'fe7baa18...'. The internal store of the MD5 of the audio signal is, in fact, completely unchanged by any metadata modifications I do to the file.
But this is only half the story: knowing that there's a 'fingerprint' of the audio signal written to the FLAC file when it's first created, and that this fingerprint isn't modified by applying any amount of metadata to the file in the form of tags, is a start. It gives us a fingerprint of 'this is what the audio signal was like'... but without the ability to create a new fingerprint of the audio signal as it is today, we can't tell if the audio signal itself has changed over time.
Enter the ffmpeg program: for it can generate new 'fingerprints', of the audio signal only, not the entire file, so it too is immune from modifications you may legitimately make to the tag metadata in the file. Here's how we can use that program to generate a new MD5 value for an audio file:

It's a fairly ugly command -though anyone who's used ffmpeg in the past for anything at all will recognise the degree of ugliness is pretty standard fare! Basically, the command is saying the "input file" (using the -i switch) is my '02 - Allegro.flac' file, and it's asking it to create a new MD5 hash value for that file, piping a lot of the program's output off to nowhere (/dev/null), meaning that it won't display everything it does. Instead, it just displays the freshly-calculated MD5 hash value. You should recognise that 'fingerprint' by now... so we know the current contents of this file's audio signal is the same as the day the file was first created. The file is not, therefore, internally corrupt or changed in any important way.
Let's check once more that this new ffmpeg-derived MD5 fingerprint isn't affected by ordinary tagging activities:
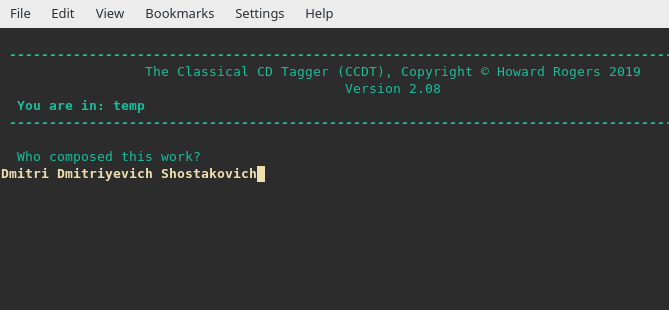
That's me adding a new composer name to the track: I would never normally use Shostakovich's patronymic name (the middle one), so I know for certain that this is new data which is being written to the file which was not there before:
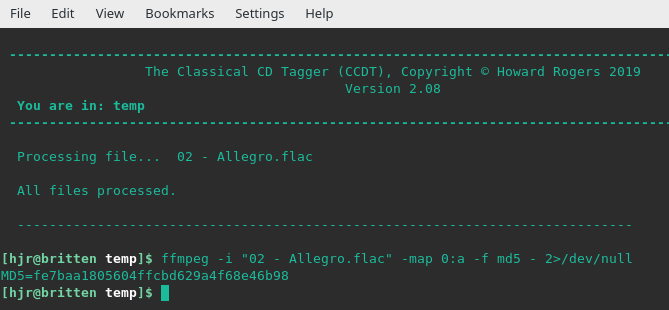
...and yet, the same old MD5 'fingerprint' is freshly computed. So no, modifying the tag data in this file doesn't alter the actual audio signal it contains, so the fingerprint remains constant. The only thing that would result in a change in the freshly-computed MD5 value is if something were to alter the audio signal itself (corruption, basically).
So do you see a way we can now check a FLAC file for internal corruption of the audio signal over time? The fingerprint displayed by the metaflac --show-md5sum is a stored one, created when the file was first created. But the fingerprint computed when we run the ffmpeg... command is a fresh one, computed from the audio signal as it is right now. Provided the two fingerprints match, we know the audio signal is the same now as it was when the file was first generated. But if they don't, we know something is amiss.
5.0 The Genesis of a Script
From the above, we could generate a simply Bash script that would do something like:
for f in *.flac; do
ORIGINALMD5=$(metaflac --show-md5sum "$f")
NEWMD5=$(ffmpeg -i "$f" -map 0:a -f md5 - 2>/dev/null)
echo "Original: "$ORIGINALMD5
echo "New: "$NEWMD5
if [ "$ORIGINALMD5" == "$NEWMD5" ]; then
echo "OK: No corruption!"
else
echo "Bad news: Corruption detected"
fi
done
Hopefully, this makes sense! We basically loop through every FLAC file in a directory. For each file, we extract the stored fingerprint with the metaflac command; we compute a new fingerprint, with the ffmpeg command; and then we compare the old and new fingerprints. If they're the same, great! If not, then bad!
It's simple enough in theory, but it won't actually work properly! Have a look at me running it:

You see that the ffmpeg command to compute a new fingerprint actually sticks the text "MD5=" onto the front of the actual fingerprint hash value. The original and new MD5 hash strings will therefore never equal each other, and every file will therefore be declared internally corrupt!
Fortunately, this is easy to fix. We just need to modify things very slightly so that we only read the 'new' hash after the equals sign, ignoring anything before it. The magic ingredient to do that is a little piece of hieroglyphics that invokes the sed program:
ffmpeg -i "$f" -map 0:a -f md5 - 2>/dev/null | sed s/.*=//g
...means 'calculate a new hash as before, but this time, get sed to strip off anything before the equals sign, plus the equals sign itself. Let me add that into my earlier script and see how we get on now:

Bingo. Now that the 'new' fingerprint lacks the 'MD5=' bit, its contents exactly match the stored one and thus the file is declared corruption-free. This is then a legitimate basis on which to routinely check your FLAC files for internal corruption.
6.0 It's all in the timing...
There's just one problem with my script as it stands: it checks everything, every time it's run. Remember from the start of this article, we could do that much more simply just by running flac -t. What I said I wanted, when I was discussing that idea, was a way to say 'this file was recently checked, so I'm not going to check it again; this file wasn't checked recently, so it's time I checked it afresh'. I wanted, in other words, a way to date my checks, and thus to be able to compare dates to work out how long ago a file was last checked for consistency.
Enter the TAGDATE! If my proto-script was to add a new piece of metadata to my file indicating 'today, right now', then that would introduce into the file a sort of 'last checked timestamp'. I could then modify my proto-script to read that stored date, compare it with the current one, and work out how long ago a file was checked for consistency. If it was old enough, then we could re-check it; if it was checked recently, then we could skip it ...and save ourselves the CPU and memory resources that are used when generating fresh MD5 hashes.
Conceptually, we can write a new tag to a file with this sort of command:
tag=TAGDATE;metaflac "--remove-tag=$tag" "$f" tag=TAGDATE;metaflac "--set-tag=$tag=$(date +%s) "$f"
The first command removes the data set for the TAGDATE metadata tag, if it's there at all. The second command adds a new piece of metadata, called TAGDATE, setting it to whatever the current date is. The slight twist is that it uses the "%s" formatting switch of the 'date' command to store the current date as a number of seconds since January 1st 1970. This makes computing things easier, since it's much easier to compare the numbers 7864857 to 8545747 than to compare the texts "June 23rd 2019" with "July 4th 2020". I can incorporate this sort of thing into my proto-script like this:
for f in *.flac; do
THISTAGDATE=$(metaflac --show-tag=TAGDATE "$f" | sed s/.*=//g)
CURDATE=$(date +%s)
if [ $("$CURDATE"-"$THISTAGDATE" |bc) -gt 1000 ]; then
ORIGINALMD5=$(metaflac --show-md5sum "$f")
NEWMD5=$(ffmpeg -i "$f" -map 0:a -f md5 - 2>/dev/null | sed s/.*=//g)
echo "Original: "$ORIGINALMD5
echo "New: "$NEWMD5
tag=TAGDATE;metaflac "--remove-tag=$tag" "$f"
tag=TAGDATE;metaflac "--set-tag=$tag=$CURDATE" "$f"
if [ "$ORIGINALMD5" == "$NEWMD5" ]; then
echo "OK: No corruption!"
else
echo "Bad news: Corruption detected"
fi
else
echo "File was recently checked. Skipping..."
fi
done
Hopefully, this is still readable, even if you're not a programmer! For each FLAC file found, THISTAGDATE is set to whatever the file's existing TAGDATE is, if it has one. CURDATE is set to the current date, in seconds after January 1st 1970. If the file's TAGDATE is more than 1000 seconds older than 'now', the file is checked. If it isn't, then the file will be skipped. It sounds reasonable and it will almost work! If you try it as written, you'll actually get an error, however:
bash: [: 1587221298-: integer expression expected
This is simply fixed by piping the result of the 'take today's date away from the previous check date' through the 'bc' program, which converts the maths result into an integer that can be evaluated properly. We also need to make sure that if TAGDATE is empty (because the file has never been checked before), then we force it to be 0, otherwise we'll end up trying to do a subtraction of null from some number... which will produce another error.
In terms of the proto-script, we're now looking at something like this:
for f in *.flac; do
THISTAGDATE=$(metaflac --show-tag=TAGDATE "$f" | sed s/.*=//g)
if [ -z $THISTAGDATE ]; then THISTAGDATE=0; fi
CURDATE=$(date +%s)
DATEDIF=$(echo "$CURDATE"-"$THISTAGDATE"|bc)
if [ "$DATEDIF" -gt "1000" ]; then
ORIGINALMD5=$(metaflac --show-md5sum "$f")
NEWMD5=$(ffmpeg -i "$f" -map 0:a -f md5 - 2>/dev/null | sed s/.*=//g)
echo "Original: "$ORIGINALMD5
echo "New: "$NEWMD5
metaflac "--remove-tag=TAGDATE" "$f"
metaflac "--set-tag=TAGDATE=$CURDATE" "$f"
if [ "$ORIGINALMD5" == "$NEWMD5" ]; then
echo "OK: No corruption!"
else
echo "Bad news: Corruption detected"
fi
else
echo "File was recently checked. Skipping..."
fi
done
...which is very similar to the previous code example, but just has a slightly neater way of computing the 'today-then' difference, using 'bc'.
Incidentally, why pick 1000 as the cut-off point? No reason, really: it amounts to about 17 minutes of time, which is quite short. It's just an example, allowing me to do multiple runs of the code quickly to see it if will actually work, once 17 minutes has elapsed. If I was really impatient, I'd probably reduce it to '10' or '100', so that the file would be considered old enough to re-check very quickly indeed. On the other hand, in real life, I'd want the time before a file is considered overdue for a check to be something much, much longer -such as 30 days, which would mean I'd have to set the time factor to 2,592,000 (which is exactly 30 days expressed as a number of seconds). But for my testing purposes, 1000 seconds will do.
The key thing to get from this proto-code is that it provides a differential check of audio files. If it was checked a long time ago, then it will expend the effort required to check it fresh; but if it was checked recently, it won't. By adjusting that 1000 seconds figure, you can control when a file is considered 'due for a fresh check'.
7.0 The Catch and The Fix
There's just one catch with my scripted, differentiated check of audio file integrity: it modifies the file once it has been checked. The lines...
metaflac "--remove-tag=TAGDATE" "$f" metaflac "--set-tag=TAGDATE=$CURDATE" "$f"
...actually remove the old TAGDATE from the file and then write a new one to it, so that the file has a record of when it was last checked. But that removal and re-write modifies the file, so that the date stamp on the file will change:
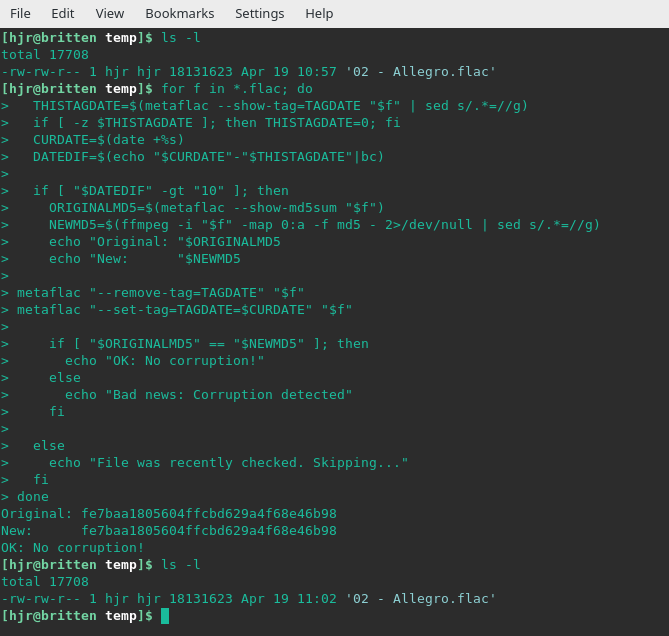
I start by displaying the timestamp on my 02-Allegro.flac file: it says "April 19th, 10:57". I run my code (with the time-selector set to just 10 seconds, so the file will definitely be considered ripe for re-check), and then I re-display the timestamp in the file: this time, it says 'April 19th 11:02'.
Now, fundamentally, updating the timestamp on a file doesn't mean a lot. It's not like the audio signal has been modified in any way, after all.
However, if you're sensible, you'll be backing up your music collection from time to time and a lot of backup software uses the timestamps on files to work out if it needs to take a fresh copy of the file or not. That is, differential backup tools (such as rsync, for example) will see the timestamp modification I've just demonstrated to you as a trigger to perform a fresh backup of the file in question. For one small FLAC file, of course, that's not really a problem: but if you were to refresh the timestamps on an entire FLAC collection of around 1.2TB in size, then all 1.2TB will have to be freshly backed-up afterwards. Even though the script can be set to not re-check a file until, say, 30 days have elapsed, that would still mean your backups would be zero for 29 nights and then 1.2TB on night 30!
The fix for this is to stagger your file checks, so that only a small part of your music collections falls due for a re-check each night. For example, say you checked your 'A' music on the 1st of a month; the 'B' music on the 2nd; the 'C' files on the 3rd and so on. On January 1st, therefore, all your 'A' music files will be checked for corruption and thus have their TAGDATE changed, causing their timestamps to be modified as well. When your backup kicks in that night, it will see that all the A files need to be re-backed-up. But the Bs, Cs and so on won't.
On January 2nd, the As will be skipped for checking, because they're now only 1 day old as far as the checking script is concerned; but the Bs will all get checked and their TAGDATE refreshed, resulting in their timestamps being changed. So the backup on the 2nd of January will have to back up all the B files, but the As and Cs won't have timestamps different from those seen in the last backup and will therefore not need to be skipped.
This pattern repeats until the 26th of the month, after which no more files are checked and thus no more get included in a nightly backup. Only when February 1st comes round do the A files get hit again, and the cycle begins once more.
By partitioning your music collection, in other words, and checking only one 'partition' per night, you limit the number of files which appear to 'change' as far as your backup software is concerned.
You can use the nights at the end of the month (from about day 27 onwards) to do 'full collection' checks. In theory, these checks will skip over every file that it encounters, because they will all have been checked for corruption within the past 30 days. Thus a full music collection check on the 27th, 28th, 29th and 30th of a month should do very little work at all and be completed very quickly in consequence. It will also not modify any file's timestamp, so it won't screw up the size of your backups. However, if you've added any new files to any part of your collection at odd times throughout the month, these full-collection checks will be able to pick them up and do an integrity check for just those newly-acquired files.
8.0 Summary
So I want to conclude by summarising what I've been saying so far. If your music collection consists of FLAC files, you should routinely and periodically check them for internal corruption. We can do this by comparing a freshly-computed MD5 'fingerprint' for the audio signal within the FLAC file with the original MD5 fingerprint that was stored within the file when it was first created. If the fingerprints differ, we can be certain that the audio signal has changed between creation of the file and now -and that's a trigger to re-rip the original CD or restore a good version of the FLAC from a backup.
These MD5 fingerprints are known not to be changed by alterations to the metadata 'tags' that are used to describe things about the music, such as composer, performer, recording date and album art, so only changes in the actual audio signal are picked up.
We can script this check so that only files which were last checked more than a defined period ago (say, 30 days) get re-checked. Files checked more recently than that defined period are skipped. Our checking strategy should be 'partitioned' so that only a part of the entire music collection gets checked at a time. This prevents our backups from taking huge hits every night. At the end of the month, we can perform 'full collection' checks which should skip past most files quickly, but will pick up and check any newly-acquired music files.
9.0 The AbsolutelyBaching.Com Flac Checker
The scripting examples I produced earlier in this article were just that: examples of how you could go about the process of scanning FLAC files and detecting any internal corruption. The code samples aren't terribly clever or well-written and lack a lot of error-trapping and other bits of finesse you'd normally expect to see in code! But the principles I discussed and which those code samples were hinting at have been properly embodied in The AbsolutelyBaching.Com Flac Checker (which shall hereafter be referred to as the ABC FC or, rather more concisely, as the AFC.
AFC is a script that can be downloaded from here.
It's free to use, but is supplied with no warranties, even for fitness for purpose. It's a Bash shell script, so you are encouraged to open it in whatever text editor you fancy to see what it does and how it does it. At it's heart, however, at around lines 190-220 is exactly the logic that was demonstrated earlier in this article's sample code snippets.
Like all software, it has some prerequisites. If you have already downloaded and run CCDR and/or CCDT, you already have everything required to run AFC. But a software installation of the following will take care of everything (even by re-installing what you already have installed):
sudo pacman -Sy flac bc
Pacman -Sy is Manjaro’s command to install fresh software packages. On other distros, you may need to use equivalent apt-get install or dnf install commands instead.
Once those prerequsites packages are installed and you have downloaded AFC itself (let's say in your own Downloads folder), you should issue the following commands:
cd sudo mv Downloads/afc.sh /usr/bin/afc.sh sudo chmod +x /usr/bin/afc.sh sudo ln /usr/bin/afc.sh /usr/bin/afc
That is, effectively, the installation script for AFC. Once run, you can invoke the program as a non-root user, simply by opening a new terminal session and typing the command:
afc
In this form, however, the program will assume that you intend the current directory to have its FLAC files checked, which is probably not what you want! To better control what the program does and where it tries to do it, therefore, there are four possible 'command line switches' which you can supply when invoking AFC:
afc --music=<path> --logdir=<path> --verbose --force --checkdays=<number>
Taking each of these run-time options in turn, then:
- --music = the absolute path to where your music files are stored
- --logdir = the absolute path to where you want the log file written to
- --verbose = turns on detailed logging, including full filenames of every music file checked or skipped. By default, verbose logging is OFF.
- --force = forces the re-checking of FLAC files for corruption no matter when they were last checked
- --checkdays = a number of days to wait between checks, over-riding the default of 30 days
So, for example, I might do this:
afc --music=/music/flac/hjr/classical/X --logdir=/home/hjr/Logs --force
That will check just my 'X' music files (there aren't too many of them, since few composers had first names that started with 'X'!), write a summary-only log to my personal Logs folder. It will also re-check all 'X' FLAC files, regardless of when they were last checked. If issued in a terminal session, the output of that command will look as follows:
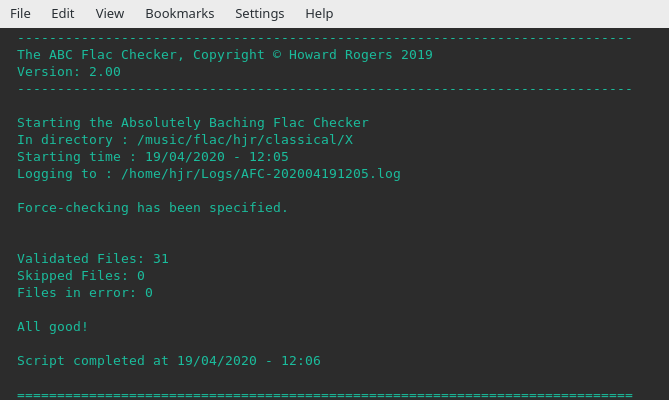
You can see here that the "--force" option has switched on force-checking (so the date of the last check for corruption will be of no consequence: all files get re-checked regardless). You get summary-level statistics about the number of files:
- checked and found non-corrupt
- checked and found corrupt; and
- not-checked but skipped because they were last checked too recently
If no files were found to be corrupt, you get an 'All good' message. The program always generates a log file: its contents will match what you see on the screen when you run the program interactively. Log files are named AFC-something.log, with the "something" being a date stamp in year, month, day, hour and minute format. If you run AFC twice within a minute, the log records from the second run will be appended to the end of those from the first.
Here's me running exactly the same command, but this time I'm going to add a "- - verbose" switch:

So "verbose" mode means each file is listed in full as it is checked (or skipped). You can imagine that this becomes very awkward to read very quickly when you have thousands of files being checked and with paths and file names that are very long! That's why AFC defaults to only outputting summary statistics! If a file is found to have a new MD5 fingerprint that differs from the one stored within the file at the time of its creation, the path and filename are always output, even if verbose mode has not been enabled. Corrupted files are always listed in a highly-visible manner, in other words.
If you specify an invalid music folder, the program will detect this and error:
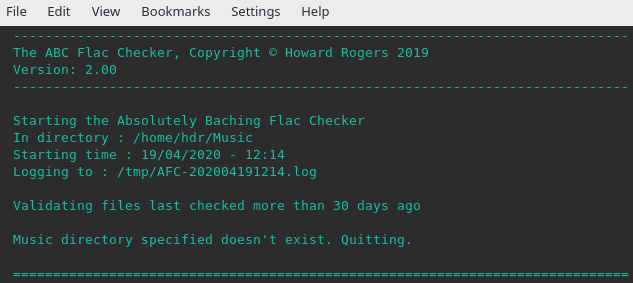
You will note here how I asked it to check "/home/hdr", when the directory that actually exists is /home/hjr. The program notices this and therefore quits without attempting to do any work.
If you don't specify a log directory when invoking the program, AFC will use the music folder to store the log. If that music folder is itself invalid (as in the above example), then /tmp is used to store the log. If you specify a log should be written to a directory that you don't have permissions to use, then the log will be written to /tmp instead. So, if my runtime command was:
afc --force --logdir=/root
...this happens:
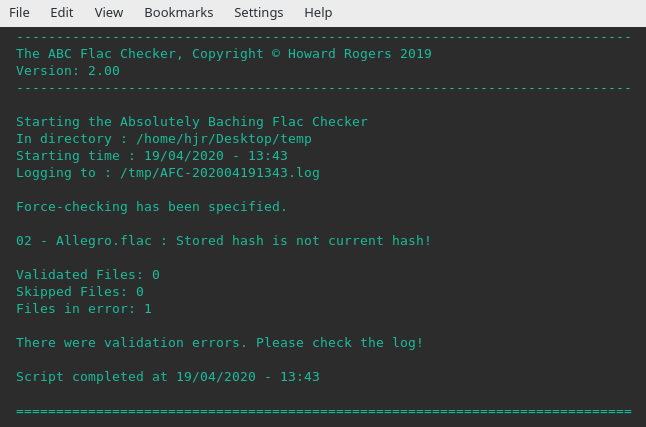
Pay attention to the "Logging to..." line. In this case, it says it will log to /tmp, because I don't have permissions to write to /root (unsurprisingly!)
That last screenshot also shows you what will happen if a file is checked and the computed fresh MD5 'fingerprint' doesn't match the one stored in the file when it was first created: notice in particular the "Stored hash is not current hash" message, and that it tells you the filename that has failed validation. If you encounter this error, there's not a lot you can do about it. The audio contents of your file have changed for some reason, but the change cannot easily be reversed. You can obviously re-rip the file from the original CD, or restore a version of the FLAC file involved from a backup old enough to not be corrupt. If either of those options are not viable for you, however, you could play the file and hope that the error is not an audible one. If it isn't, then you can convert the dodgy FLAC into a WAV, and convert the WAV back into a fresh FLAC -at which time, the 'stored hash' is re-computed by the flac program itself. The file will then pass a future validation -but you must understand that if this happens, the contents of the FLAC file are not genuinely 'clean'; you have simply worked around the problem, but you haven't actually resolved it. So, AFC will tell you when your files are corrupt, but the fix is entirely down to you. AFC cannot and will not 'repair' a corrupted FLAC.
AFC, by default, sets the time between checks to be 30 days. In other words, if a file was checked on day 1, it won't be selected for a re-check until day 31. Default runs of AFC on any of the intervening 30 days will produce a 'skipping this file' message. You can override this behaviour by specifying --force, of course: that effectively sets the 'time to wait between checks' to 1 second, so that every file is almost immediately considered 'due for a re-check', no matter how often you run AFC. A less aggressive override is also provided by the --checkdays=<something> option. Type in '6' (say) as that parameter value and you are saying "If the file was last checked at least 6 days ago, then re-check, otherwise skip":

Here, you see that the message is 'validating files last checked more than 6 days ago', because my AFC command included a --checkdays=6 parameter. In this case, because I've already forced the files in this folder to be checked previously, no files meet the '6 days old' requirement, therefore, all are skipped and none are actually checked.
The checkdays and force parameter are mutually exclusive. If you specify them both, then the force parameter will win out and the 'time to wait before re-checking' will be set to 1 second, regardless of what the checkdays parameter is set to.
The AFC program will run interactively (as you can see from the previous screenshots), but it is really intended to be scheduled to run non-interactively, via a crontab. Here is a snippet from my own crontab:
# Check of FLACs for internal consistency, one letter per night
# -------------------------------------------------------------
0 2 1 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/A" --logdir="/home/hjr/Logs" --force
0 2 2 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/B" --logdir="/home/hjr/Logs" --force
0 2 3 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/C" --logdir="/home/hjr/Logs" --force
0 2 4 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/D" --logdir="/home/hjr/Logs" --force
0 2 5 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/E" --logdir="/home/hjr/Logs" --force
0 2 6 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/F" --logdir="/home/hjr/Logs" --force
[...]
0 2 23 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/X" --logdir="/home/hjr/Logs" --force
0 2 24 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical/Z" --logdir="/home/hjr/Logs" --force
0 2 25 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
0 2 26 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
0 2 27 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
0 2 28 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
0 2 29 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
0 2 30 * * /usr/bin/afc.sh --music="/music/flac/hjr/classical" --logdir="/home/hjr/Logs"
As discussed in the main part of the article (Section 7), my music collection is 'partitioned' into alphabetical sections, depending on the first name of the composer involved (so Beethoven is filed in the L section, since his first name was Ludwig; Mozart is consigned to the 'W' section, for hopefully obvious reasons!) My crontab checks the As on day 1, the Bs on day 2, the Cs on day 3 and so on. These are forced checks: it doesn't matter how recently the contents of those alphabetically sorted folders and sub-folders might be, the audio files will get re-checked on their appointed day. The alphabetical checks conclude on the 24th of the month (since I have no Qs or Ys as yet). For the 25th until the end of the month, therefore, I do full collection checks, regardless of alphabetical section, but don't expect these to actually do much work, since almost everything will have been checked within the past 30 days by then. These 'global checks' are therefore not forced, because I wouldn't want to do daily checks of my entire music collection! However, these 'full collection' checks will pick up new acquisitions that I might make during the month. If I buy a new piece of Benjamin Britten on the 15th of the month, for example, it will be checked on the 25th of that same month, rather than having to wait until the 2nd of the next month (which is when 'B' pieces would ordinarily get checked).
10. Conclusion
If you rip your music to FLAC, I can assume you care about audio quality. This article has sought to explain what methods are available to you to check and ensure that your audio files continue to be bit-perfect. In particular, it has suggested the use of the AbsolutelyBaching Flac Checker (AFC), which I use myself every day to ensure my own substantial music collection remains in perfect working order (or to alert me if and when, for some reason, any part of it stops being perfect!); I hope you too will find AFC useful in keeping your own music collections in good order.