 It's been a little over a fortnight since I modified my AMP player to work with a database -and, when it does so, to record every 'play' it decides on in a database table of its own.
It's been a little over a fortnight since I modified my AMP player to work with a database -and, when it does so, to record every 'play' it decides on in a database table of its own.
So now, 15 days later, I can analyze that 'plays' table to determine if AMP has been doing the job I designed it for: picking a wide variety of composers and music genres, at random, and thus not creating any 'favourites'!
The first results look good. Click on the thumbnail image at the left and you'll see a summary of my last fortnight's plays by composer. In all, AMP has played music from 152 different composers and -as the chart shows- nearly all of them have been played once only. Ten composers have been played twice; two have been picked on three times (John Rutter and Georgy Sviridov, as it happens).
That's a fairly even and wide-spread distribution of composer choices, so I think we can see that randomisation works for achieving the 'I have no favourites' look!
The net effect of AMP in this regard is quite noticeable on this graph of my listening habits I've been keeping since August 2019:
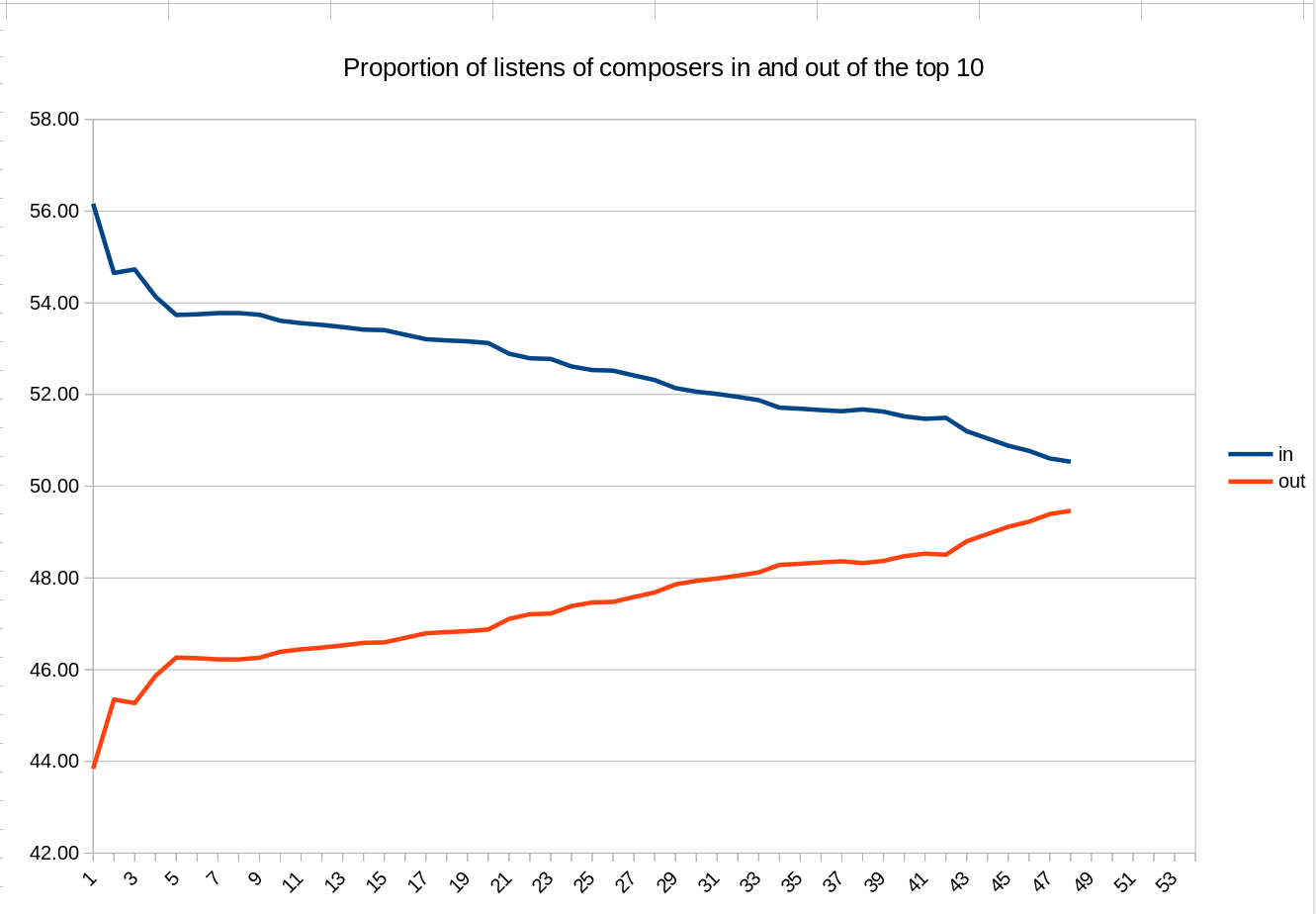
That's a plot of the proportion of total plays belonging to my 'top ten composers' (basically, Bach, Britten, Vaughan Williams, Handel, Sibelius Purcell, Shostakovich, Verdi, Rameau and Mozart), plotted in blue. The orange line then plots the proportion of plays belonging to every other composer in my collection! As you can see, I'm very 'top heavy': 10 composers account for over half my plays; the other 540-odd account for less than half of them. I've been consciously trying to 'fix' this (by not playing my top ten so much) for 18 months or so, and you can see that the orange line has steadily climbed in response.
But you'll notice that it inflects slightly upwards from about the 43rd measurement on: that is the point where I started using AMP for myself. I've configured an 'exclude' for it (see the AMP FAQ, specifically question 5) that completely prevents AMP selecting any of my top 10 composers for random play (I can override that if I feel I have to, of course!): that 'precision' in excludes has meant my orange line has definitely accelerated pace over the past few weeks.
I should be able to say that my top ten composers account for less than half of my total plays in around 2 weeks' time, which is a good few months earlier than I was expecting around the end of November last year -thanks to AMP!
Back to AMP's past two weeks of plays: what effect has it had on my choice of types of music to listen to?
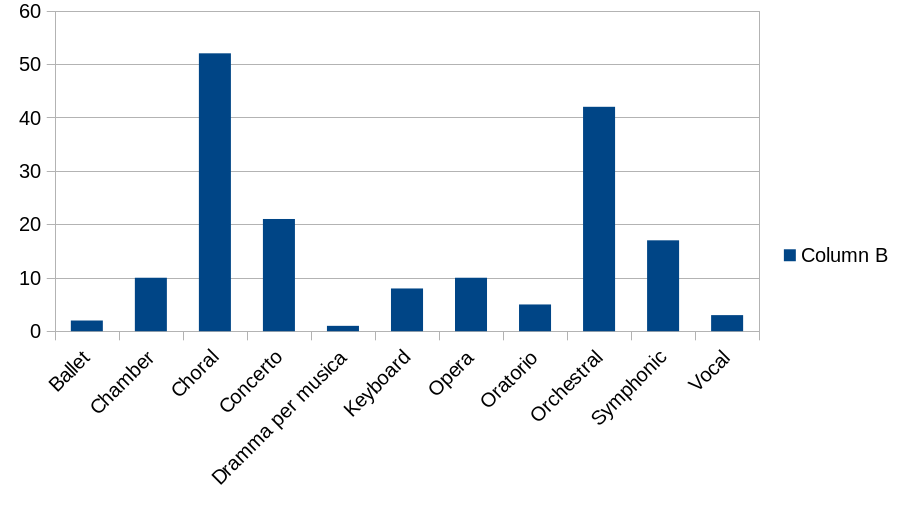 Results are not so clear-cut here, largely because musical 'genres' are quite 'lumpy' in the first place: I have a huge collection of choral, orchestral and symphonic works, and not much piano/organ stuff, so it's unlikely that a random choice would even-out the genres as much as it does the composers. The good news, however, is that there is nevertheless a widespread choice from pretty much most available genres. The bad news is that I have at least one piece of music that is badly tagged: there should be no such genre as 'Dramma per musica', so that will have to be hunted down and corrected in my collection. (Data stored in tables like this are great for showing you where your tagging has gone astray in the past!)
Results are not so clear-cut here, largely because musical 'genres' are quite 'lumpy' in the first place: I have a huge collection of choral, orchestral and symphonic works, and not much piano/organ stuff, so it's unlikely that a random choice would even-out the genres as much as it does the composers. The good news, however, is that there is nevertheless a widespread choice from pretty much most available genres. The bad news is that I have at least one piece of music that is badly tagged: there should be no such genre as 'Dramma per musica', so that will have to be hunted down and corrected in my collection. (Data stored in tables like this are great for showing you where your tagging has gone astray in the past!)
Fortunately, it's easy to track down mistakes like that. A simple query:
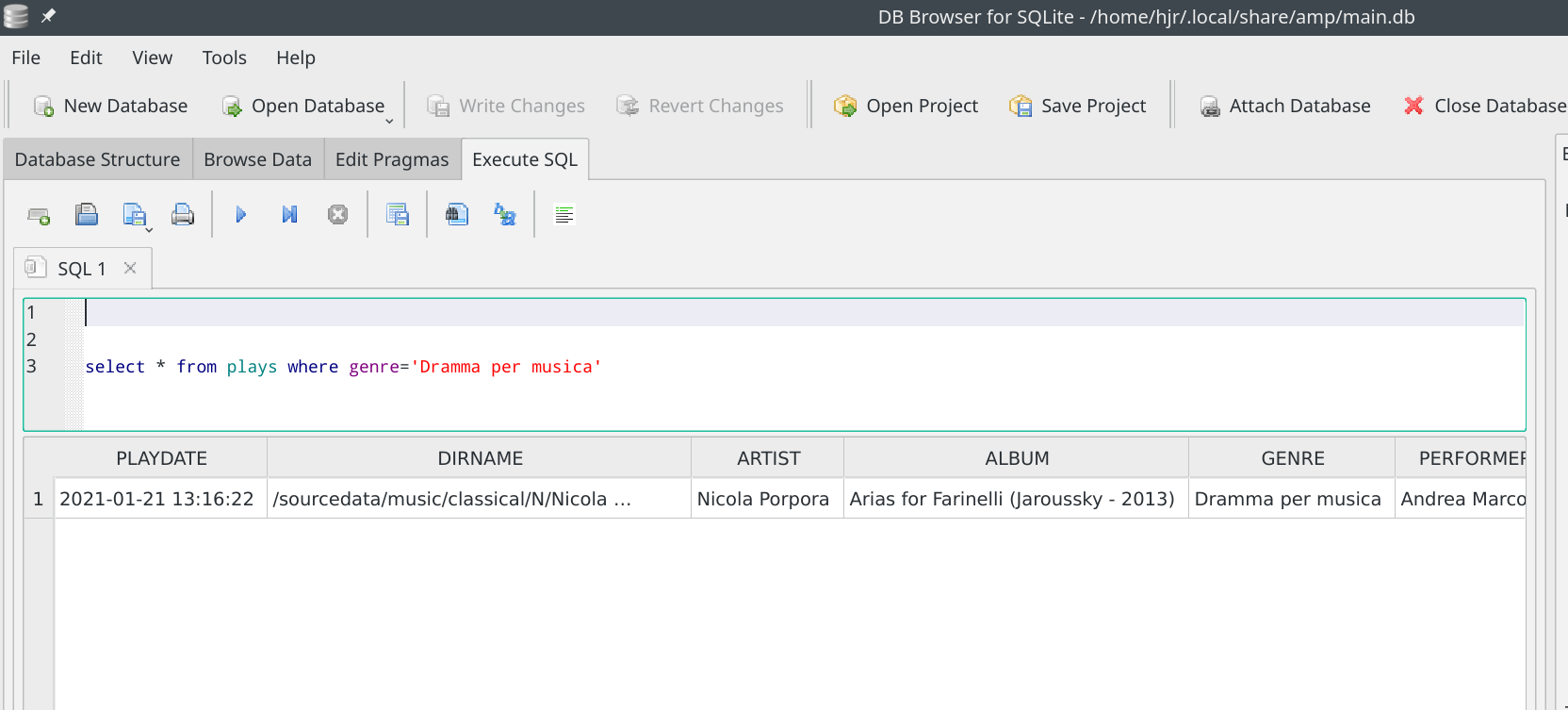
…tells me all I need to know: Nicola Porpora has a composition that has been badly tagged, so a bit of CCDT work in his folder will get that sorted for the future and a little bit of updating work in the database query tool will fix the data there too:
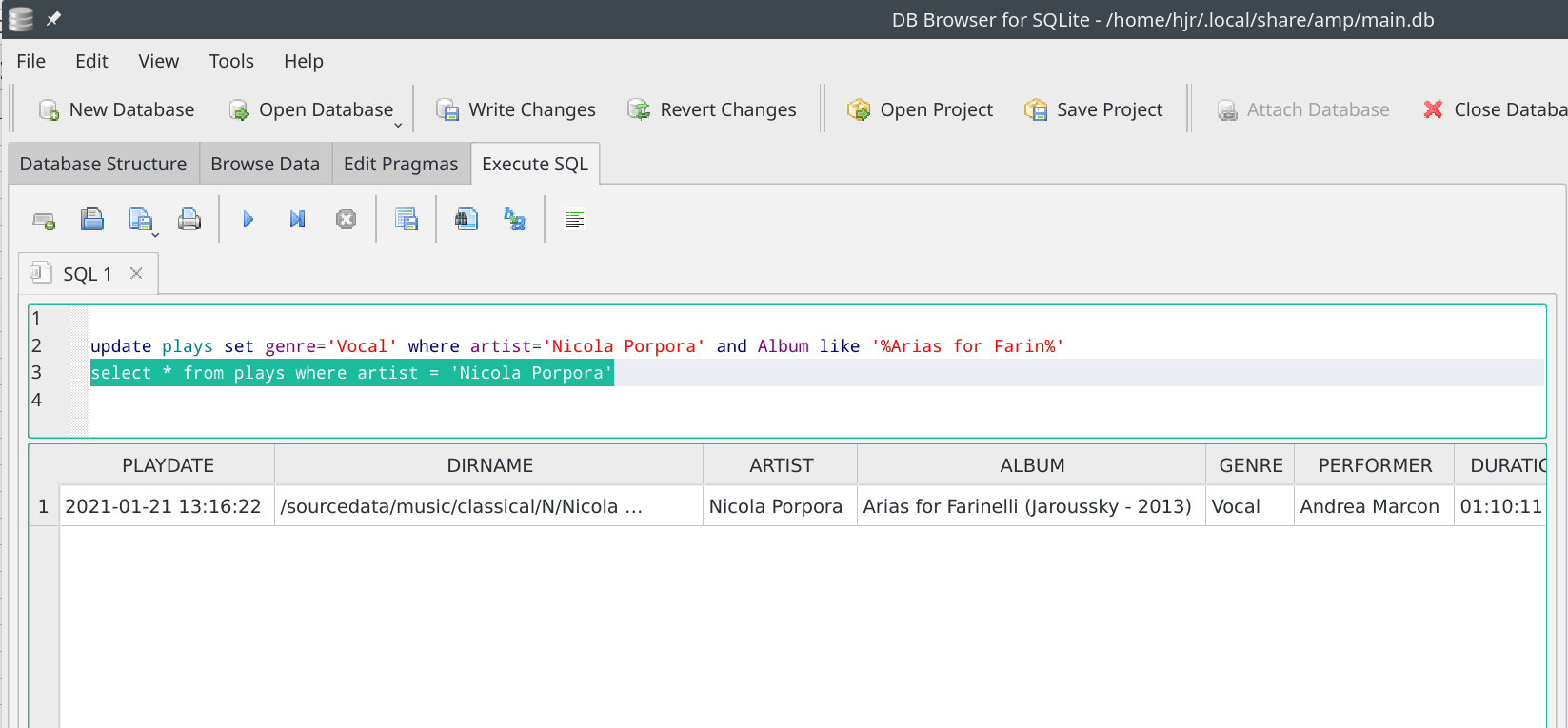
And now the play that took place at 13:16 on the 21st of January is more correctly assigned to the 'Vocal' genre.
The tool I'm using to generate these sorts of reports and data is called DB Browser for SQL Lite. It's easy to install on most Linux distros from the standard repositories; it even runs on Windows without drama. It's a simple but highly intuitive and effective way of querying the contents of any SQLite database (including the one that AMP uses!) and I recommend it as a mostly painless way of understanding your listening habits over time -and sometimes being pointed to a need to correct your metadata!